スマホでちょっとしたPythonのコードを確かめられないかと探してみると、Google PlayストアにPydroid 3というPython環境があったのでインストールしてみました。
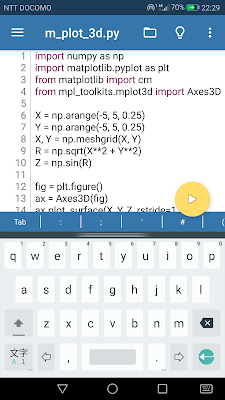
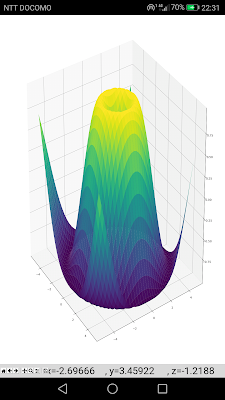
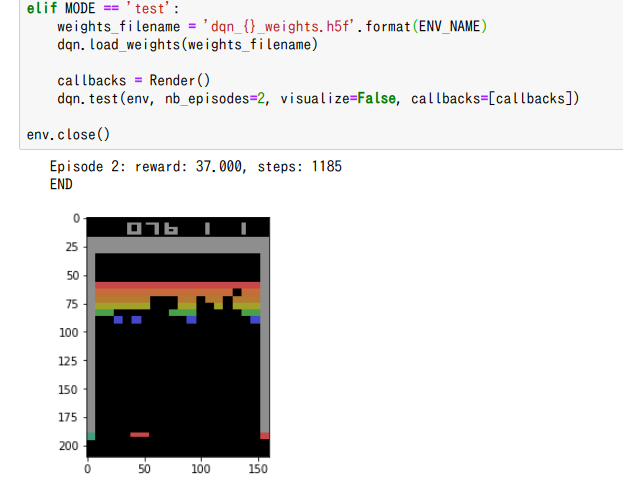
pipを使うことが可能で、numpyやmatplotlibもインストール可能。ためしにサンプル(上画像)を実行させてみました。特に問題なく動きます。
pipでインストールする方法:
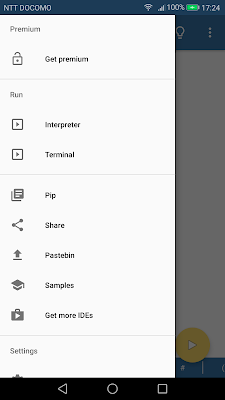
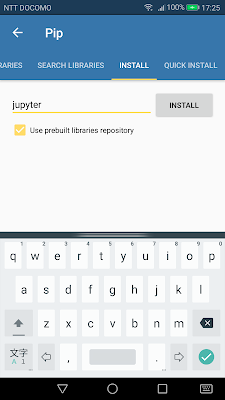
メイン画面の「≡(メニューマーク)」をタップすると、上画像左のような項目が出てくるので、「Pip」をタップすればライブラリを検索する画面になります。そして必要なライブラリ名を入力して「INSTALL」をタップ。
「QUICK INSTALL」タブには、主なライブラリがリストアップされているので、numpyやmatplotlibなどはこちらからインストールいたほうがいいかもしれません。インストールしたいライブラリが見当たらなければ「SEARCH LIBRARIES」タブで検索。
pipでJupter NotebookやKeras(Theano)をインストール:
pipの画面からKerasはインストール可能でしたが、Tensorflowは対応していないためかダメでした。そのかわりTheanoはインストールできたので、KerasのバックエンドとしてTheanoが使えます。
追記:
その後アップデート(2019年4月)があったようで、有償版にすればTensorflowもインストールできるようになっていました。
最近パソコンではJupyter Notebookばかり使っているので、スマホの方にもインストールしてみることにしました。
ターミナル画面からJupyter Notebookを起動:
基本は.pyファイルで保存ですが、Jupyter Notebookで.ipynbファイルも扱うことができます。
メニュー>Pipの画面から「jupyter」をインストールし、ターミナル画面に切り替えてから「jupyter notebook」を入力して起動すると、
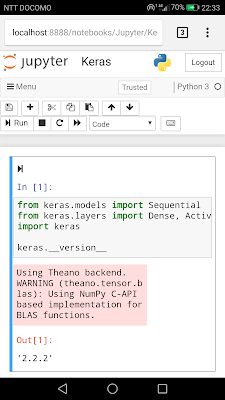
Chromeが自動的に起動してJupyter Notebookの画面が出てきました。パソコンと同じような感覚で使うことができます。Chromeが自動的に開かない場合は、ターミナル画面に出てくるURLをChromeのアドレスにコピペすればJupyterの画面になるはずです。
あまり重い演算はさすがに無理ですが、ふと思いついたコードを試すにはよさそうです。
Android 7と8での違い:
Android 7では上記の方法でJupyter Notebookは動作しましたが、Android 8の場合だとセキュリティの違いのためかChromeが自動的に起動しません。ターミナル上に出力されたアドレスをChromeへコピペするしかありません。
追記:
その後のアップデートでAndroid 8でも自動的にChromeが立ち上がるようになっていました。
問題なのが、Jupyterが起動したあとPydroidのカーネルが途中で落ちてしまいます。マルチウィンドウ(二窓)でChromeとPydroidを起動しておけば落ちないのですが、Chromeを前面表示するとバックグラウンドで動いているPydroidが数秒で落ちてしまいます(対応策は下へ追記しました)。
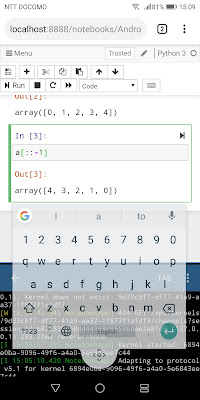
このようにChrome(Jupyter)とPydroidを上下に同時に表示させて使う分にはPydroidのカーネルが落ちずに済みます。キーボード(画像ではフローティングにしていますが)は下のほうにでるので、Pydroidのターミナル画面に重なる感じならJupyter画面にもあまり邪魔にならないかと。
画面移行してしまうとPydroidが落ちてしまいますが、再度ターミナルでJupyterを起動し、Chromeのほうは画面をこのまま再読み込みさせれば大丈夫そうです(再度アドレスをコピペする必要がない)。
追記(上記の対応策:Huawei Nova lite 2の場合):
Android 8のバッテリー最適化機能でカーネルが落ちないようにするには、「設定」→「アプリと通知」→「アプリ」から画面下の「歯車」の設定マークをクリック→「アプリの設定」→「特別なアクセス」→「バッテリー最適化を無視」の画面で「すべてのアプリ」を表示させ「Pydroid 3」を一覧から選択し「許可」するに変更。
こうすることでバッテリー最適化によるアプリの自動切断を防ぐことができ、バックグラウンドでも動き続けるようです。
Jupyter nbextensionsのインストール:
Jupyter Notebookを使う場合、nbextensionsをインストールすれば様々な機能拡張が使えるようになります。
Pydroidのpip画面で
jupyter_contrib_nbextensions
を入力(あるいは検索)してインストール。
さらにターミナル画面に切り替えて、
jupyter contrib nbextension install --user
を入力(インストールはこれで終了)。
ターミナル画面から「jupyter notebook」入力で、ChromeにJupyterを立ち上げます。
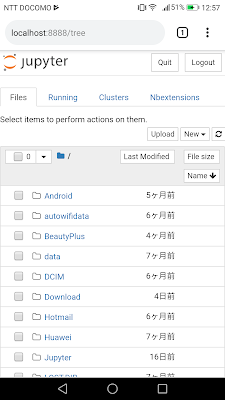
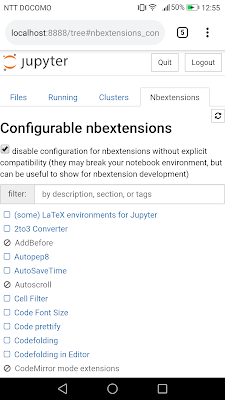
そうすると「Nbextensions」というタブが増えているので、それを選択すればさまざまな機能拡張の一覧が出てきます。
「Nbextensions」タブがない場合は、「localhost:8888/nbextensions/」にアクセスすれば出てくるはずです。
Gist itを使う:
個人的に便利だと思うのはGithubのGistへボタン一発でファイル保存する機能です。
「Nbextensions」の一覧を見ていくとでてくるので、「Gist-it」にチェックをいれておきます。
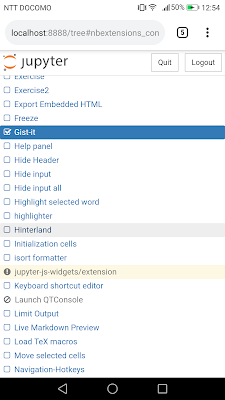
そして、コーディングするページを開けば、
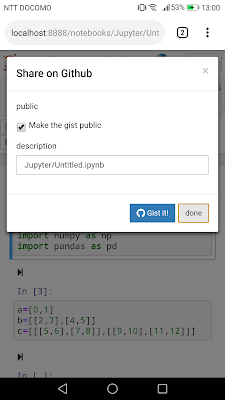
右上にGithubマークのボタンが増えているので(現れなければ画面をリロード)、これをクリック。
そうすると確認画面がでてくるので、青い「Gist it!」ボタンでアップロード(Tokenを登録する必要があります)。プライベートでアップロードしたいなら「Make the gist public」のチェックを外しておきます。
ファイルの保存先を忘れることもなく、後でパソコンからアクセスするのも容易なので便利です。
オンラインのJupyter Notebookを使う:
https://jupyter.org/にアクセスすればインストールせずにオンラインでもJupyterを試すことができるようです。
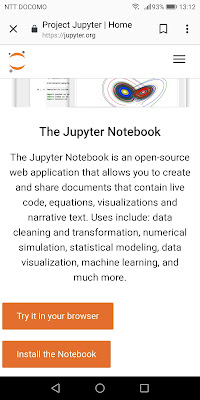

Jupyterのトップページ上の「Try it in your browser」をタップすれば、JupyterかJupyterLabなどを選択するページへ移動し、とりあえず「Try Jupyter with Python」をタップすると「Welcome to Jupyter」というサンプルページが表示されます(以下)。
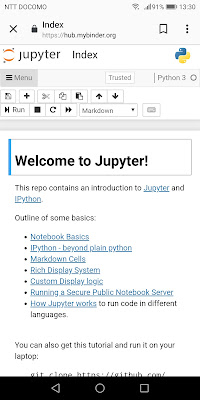
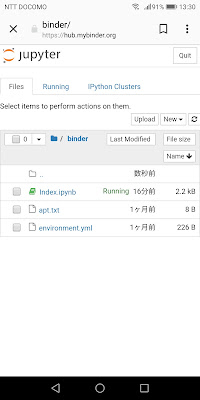
左上の「≡Menu」から「File>Open...」を選べばディレクトリ一覧のページが表示されます。
ここで右上の「New▼」から「Python3/Text File/Folder/Terminal」を選択して新たなファイルを開くことができます。
Terminalを選択すればターミナル画面に移行し、「pip list」入力でインストールされているライブラリを確認できます。Numpy、Scikit-learn、Scipy、Pandasなど基本のライブラリはインストールされているようです。TensorflowやKerasはインストールされていませんが、「pip install tensorflow」で追加インストールできるようです。
ファイルも一時的に保存できるようですが、仮想サーバのためか、一旦ログアウトしてしまうとすべては消えてしまうようです。
ちょっとしたコードを試すだけなら、このオンラインのJupyterでも十分そうです。
Google Colabをスマホ上で使う:
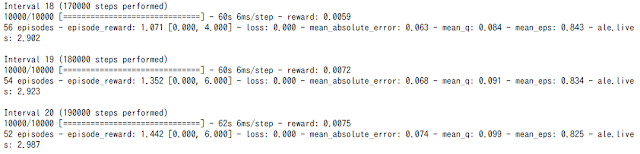
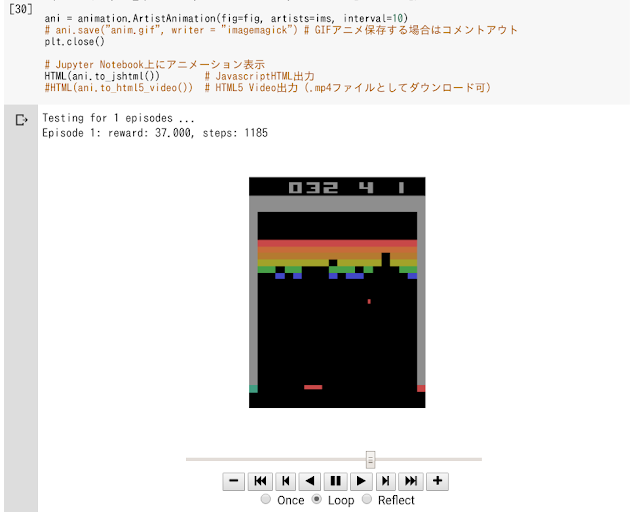
Jupyter Notebookが使えるのは便利ですが、それならGoogle Colabを使えばいいのでは?ということでColabも試してみました。Colabの場合は全ての環境はクラウド上にあるので、ChromeさえあればスマホからでもGPU利用が可能です。Tensorflow、Keras、Numpy、Pandas、Matplotlibなど基本的なライブラリはすでにインストールしてあるUbuntu環境なので便利。
この場合、先ほどのPydroid 3は無関係で、単にChromeでcolab.research.google.comへアクセスすればいいだけ。
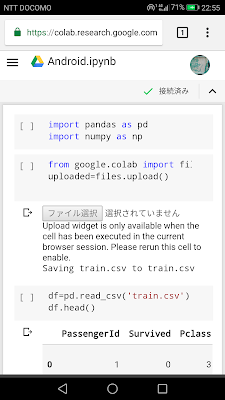
特に問題なく動きます。基本Google Driveにデータファイルなどを保存しておけば便利です。Colabの場合ならTensorflowも普通に使えるし、GPU演算なのでスマホでも問題ないという感じ。
仮想キーボードCodeBoard Keyboard for Coding:
コーディングするには、Google PlayにあるCodeBoard Keyboard for Codingが便利そうだったのでインストールしました。
既存のキーボードだと、数字や記号を入力する際に入力切替が必要だったりアローキーがなかったりするため少々不便なのですが、このキーボードであればコーディングに必要そうなキーが揃っているので便利です。コメントアウトの「#」記号だけ表面にないのですが、右上「SYM」を押せば記号一覧の中に出てきます。
まとめ:
Pydroid 3はスマホアプリなので一旦ダウンロードすればオフライン(通信料なしで)でも動く点では便利です。Tensorflowが使えなかったり、重い計算は無理なので多少の制約はあります。通信料が気になる場合はPydroid 3がいいかもしれません。ただしライブラリをインストールしすぎると1GBを超えたりするのでメモリを圧迫したくない場合は要注意。
一方、Colabの場合はコマンドのやりとりで通信料は発生しますが、演算自体はクラウド上(GPUでも可)で行うのでスマホであっても問題なく重い計算が可能という点が便利。また、ログインごとに(90分放置すると初期化)ライブラリやデータをインストールし直すのが面倒ですが、Google Driveに保存してあるデータをアップロードするのであれば、データのやりとりもクラウド上で行うのでデータが大きくてもその分の通信料はかからないはず。Colabを利用することで、スマホからでも普通にディープラーニングのコードを実行できるのはかなり画期的。Wifi環境下で通信料がかからないのであればColabがおすすめ。