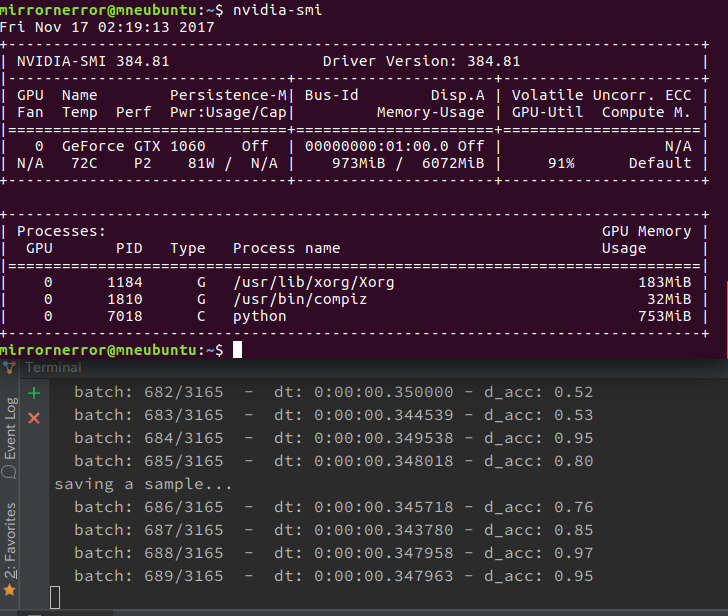
Deep Learning用ゲーミングノートパソコンの設定は一段落したのですが、使っているうちに幾つか気になる点がでてきたので少しだけ以下の環境を見直してみました。
・Python用エディタの設定
・Deep Learning用ライブラリ、プラットフォームの選定
・デュアルブートパーティションによるUbuntuへの割当量
まずはエディタに関してです。
エディタ:Pycharm/Spyder/VS Code/Atom
Pycharmが使いやすいという評判から試してみましたが、案外
Anacondaに同包されている
Spyder IDEというエディタのほうが使いやすかったです。しかしどちらもややカスタマイズしにくい。それでは人気のある
VS Codeはどうかというと、拡張性もありカスタマイズできそうだし、なにより動きが軽快。ということで、VS Codeで環境を整えていましたが慣れないこともあり、いまいち上手くいかない。それで、いままで使っていた
Atomに戻って設定し直してみると、望んでいるような使い方ができるとわかり、結局のところAtomを使うことに。AtomはVS Codeに比べてやや重い感じもしますが、パッケージの豊富さとかなりのカスタマイズ自由度があって使いやすい。
Spyder IDE:
Anaconda Navigatorからすぐにアップロードでき、比較的使いやすい印象。ただカスタマイズしにくい。ダークのthemeを選んでいるにもかかわらずフレーム部分だけは白いままで変えられない。オープンソースなので、元のソースを変えればカスタマイズ可能だろうけれども面倒。
Anaconda仮想環境に合わせたエディタ:
Atomを選んだ切っ掛けとして、Anacondaの仮想環境に対して設定がしやすいということが一つありました。Anaconda自体はかなり便利なのですが、切り替え可能な仮想環境とエディタをつなげる部分がやや面倒。要は仮想環境PATHへつなぐ設定法がそれぞれのエディタで異なっており、Atomの場合比較的簡単で自由度があったということです。
AtomとAnaconda Navigator:
Anacoda Navigatorでグラフィカルに複数の仮想環境を見比べることができるので便利。インストール/アンインストールもこの画面内で可能。仮想環境切り替えや接続に関してはAtomが比較的使いやすい。
最終的にはAnacondaの仮想環境は上画像のようにrootとpy35(Python3.5)だけにしました。それまでの仮想環境は:
・root(万が一のために備え、ここにはインストールしない/使わない)
・py35(安定版Tensorflow1.4、Pytorch0.2.0など/メインで使う用)
・py27(Python2.7にしか対応していないサンプルなどあるときに使う)
・cuda90(CUDA9に対応したα版Tensorflow1.5やソース版Pytorchなど/最新版実験用)
という感じで複数の仮想環境を使い分けて、どの環境が使いやすいか試していました。ライブラリやパッケージを入れすぎて不具合が出ても、仮想環境ごと消してしまえばいいのでシステムに影響を与えずに済みます。
Tensorflowなどを最新版(α版)にすれば最速になるのかと思いましたが、結局のところまだ不具合があったりサンプルも対応していなかったりとあまり使い勝手がよくない。ということから、サンプルも豊富な安定版を使ったほうがいいという結論に達しました。
Atomのパッケージ:
主には仮想環境の切り替えと接続が容易ということからAtomでの環境整備。MacBook Proのほうでは便利そうなパッケージをどんどん入れていましたが、今回はシンプルに最低限必要なパッケージだけをインストールしました。いまのところ標準装備のパッケージ以外3つだけで充分です。
・autocomplete-python
・platformio-terminal(このターミナルが使いやすい/Python RUN用)
・script(Python RUN用)
ネットで検索するとほぼ英語圏のサイトが多いことから英語表記のほうがわかりやすいため、日本語化しないことにしました。既存のOne Dark:Themeを使っていますが、フォントサイズや見た目的なカスタマイズは、Edit>Stylesheetからstyles.lessファイルで上書き変更しています。
PythonスクリプトをRUNさせる環境:
ここが一番悩んだところで、AtomのなかにもいくつかPythonスクリプトを実行できるパッケージがあり、ただRUNさせるだけであればどれでもいいのですが、ターミナルを使って実行させる方法とボタンやショートカット一発で実行できるものということ、そして仮想環境や作業ディレクトリの切り替えが即座にできるということから、
platformio terminalと
atom-scriptを選びました。
Anaconda仮想環境切り替え方法:
Anacondaの仮想環境を使っていると、毎回ターミナルで入力が必要になります。通常は以下の状態(Anaconda root:Python3.6):
そして、以下を入力すると、
$ source activate py35
先頭に(py35)という表示がでて、仮想環境py35:Python3.5に入ったことになります。
追記:現在は「conda activate py35」に
変更済み。
which pythonを打てば、どのPython interpreterを使うかという違いが分かります。いわゆるPythonのPATHについてです。
これは、which pythonをつかって両方の環境のPATHを確認してみた画面です。最初のwhich pythonがAnaconda/rootのPATHです。つぎのwhich pythonがAnaconda/py35のPATHになります。
実際のところ仮想環境はAnacondaだけでなく、その手前にpyenvでも仮想環境をつくっています。anacondaで色々試しているため、anaconda内部で不具合が起きてしまったら、pyenvでanacondaごとアンインストールしてしまえばいいというわけです(実際一度anacondaを入れ替えました)。
platformio terminalの設定(かなり便利):
platformio自体は
以前ESP32を試したときに使ったことがあるのですが、今回のようなPython用には設定していないので、あらためて使い直すという感じです。
Packages>Settings>Manage Packagesでインストール済みのパッケージリストからplatformioのsettingsボタンを押して各種設定に入ります。
主には、一番上のほうに出てくるこのあたりを設定します。
特にToggles欄の上から4番目の「Run Inserted Text」と5番目の「Select To Copy」にはチェックを入れておきます。
次にCore欄の、「Auto Run Command」に先程の仮想環境を切り替えるコマンドを入れておきます。ここではさらに、「which python」でPATHの確認、ディレクトリ内のリスト表示させる「ls」もセミコロンで区切っていれてあります。
その下の「Map Terminals To」でタブから「File」を選びます。
こうすると、platformio terminalが自動的に仮想環境に入って、しかも選択ファイルのディレクトリに移動して開いてくれます。
ファイルを切り替えるごとに、
source activate py35
which python
cd ${File}
ls
これらを自動的にやってくれて、仮想環境移行/PATH確認/作業ディレクトリへ移動/ディレクトリ内のリスト表示が一気にでてきて、実行する前の確認や手続きが一発で済みます。
ほかにもターミナルのパッケージがありますが、ここまでできるのはplatformio terminalくらいかもしれません。かなり便利です。
あとはプログラムをRUNさせるだけでいいのですが、もう一つ問題があります。
コマンドオプション付きのPythonプログラムの実行:
PytorchサンプルなどをRUNさせるときによくあることですが、
Python Argparseでコマンドオプション(CUDAの有無やイテレーションの設定など)を追記する必要があります。
Pytorch
examples/dcgan/main.pyをRUNさせる場合(コマンドオプション):
parser.add_argument('--dataset', required=True, help='cifar10 | lsun | imagenet | folder | lfw | fake')
parser.add_argument('--dataroot', required=True, help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ndf', type=int, default=64)
parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
parser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
parser.add_argument('--cuda', action='store_true', help='enables cuda')
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='', help="path to netG (to continue training)")
parser.add_argument('--netD', default='', help="path to netD (to continue training)")
parser.add_argument('--outf', default='.', help='folder to output images and model checkpoints')
parser.add_argument('--manualSeed', type=int, help='manual seed')
このmain.pyをRUNさせるには、これだけコマンドオプションがあります。ほぼdefault(コマンドオプションなし)でもいいのですが、defaultが設定されていない--dataset、--dataroot、--cuda、--manualSeedについてはコマンドオプションが必要となります。ということから最低でも、
$ python main.py --dataset cifar10 --dataroot ./ --cuda --manualSeed 1
という感じでpython main.py以下に必要項目を追記してからRUNさせなければいけません。この部分が面倒で、すべてにdefault値を設けたコードに書き直したり、この一行をコピペできるようにコメントに書いておいたりしていましたが、platformio terminalやscriptだと比較的簡単にできました(まあ、ターミナルでそのまま打ち込んでもいいのですが)。
platformio terminalのコマンドオプション付き実行の場合:
まず、上記のようなコマンドオプション付きのコマンドをコメントに書いておきます。そして最初に設定しておいた「Select To Copy」機能によって、上記コマンド一行をマウスで選択した段階でコピーが済んでおり、あとはペーストするだけになります。さらにペーストをキーマッピングしておきます。
・platformio terminalのSettings画面で「Select To Copy」にチェックを入れておく
・platformio terminalのSettings画面の下のほうにある「Custom Texts」の「Custom test 1」に「python $F」を入力しておく
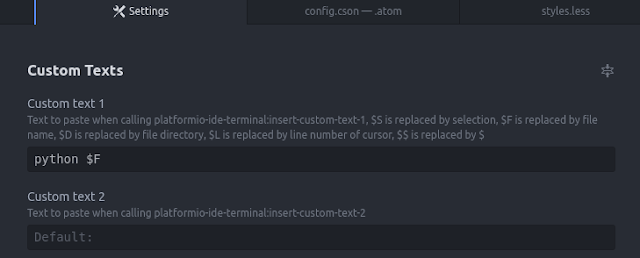
このSettings画面で設定した内容は、Edit>Config...>config.csonでも編集できます。以下のconfig.csonファイルで直接編集してもいいかもしれません。
ちなみにplatformio terminalの設定はいまのところこんな感じになっています。
・Edit>Keymap...でkeymap.csonを開きキーマップ割当をする
上記の内容をキーに割り当てることで、もう少し入力方法が簡単になります。
これはkeymap.cson内に書き込んであるキー割当のスクリプトです。
こちらを参考にしました。
alt-zで選択したテキストを実行します。
alt-xでpython fileを実行します。
コマンドオプションがある場合(例:python main.py --cuda --niter 1)は、コマンドオプションを含めた一行をどこかに書いておいて、それを選択してalt-zで実行するという感じです。
コマンドオプションが不要な通常の方法(例:python main.py)の場合は、そのままalt-xで実行します。キーマッピングなので、都合の良いキーに割当られますが、意外と既にあるショートカットキーと重複することがあるので、試し打ちしてみて使っていないキーの組み合わせを探さないといけません。
実行中停止させるコマンド:
通常ターミナルでプログラム実行中に割り込む命令としては、
一時停止:ctrl-z
ジョブ名表示:jobs
再開:fg 1(ジョブ名)
終了:ctrl-c
となりますが、ctrl-cで終了させるために、kill -9 $$やskill --fullなどをキーマッピングしてみましたが上手く機能しません。もうすこしSIGNALやシェルの勉強が必要かもしれません。最悪、途中強制終了するにはplatformio terminalの画面を閉じてしまうかです。
もしかしたら、platformio terminalはエミュレータのターミナルなのでそこまでの処理ができないのかもしれません。この部分については調査中です。
atom-scriptの場合:
atom-scriptは様々な言語に対応しており人気のあるパッケージだと思います。いろいろ改良されており、jupyter notebookにも対応、一応コマンドオプション付きでRUNさせることもできます。ただ問題はそのままだと仮想環境には自動的に入ってくれないという部分です。Pythonなどの環境変数に対応させるために
atom .
と、ドットつきでターミナルからatomを起動しろと書いてあります。これが煩わしいので、専用のatom起動用アイコン(ランチャー)をつくり、ドット付きの起動を可能にしました。
atom仮想環境用起動アイコン(ランチャー):
・「/usr/share/applications」の中の「Atom」アイコンを右クリックでコピー
・デスクトップなどにペーストし、右クリックでプロパティ画面を開く
・名前を「AtomPY35」などと変える
・コマンド欄に以下のような環境変数とドット(2箇所あり)を含めたシェルコマンド書く
*シェルコマンドについてはまだ勉強不足で不確かな部分もあるのですが、一応以下でも動きました。sourceの代わりにドット(.)を使っていますが、もしかしたらexportなど使ったほうがいいのかもしれません。
bash -ic ". /home/mirrornerror/.pyenv/versions/anaconda3-5.0.1/bin/activate py35; atom .; exec bash"
・ターミナルで新アイコンが置いてあるDesktopへ移動
cd ./Desktop
・新アイコンを「/usr/share/applications」へコピー移動する
sudo cp AtomPY35.desktop /usr/share/applications
・一度「/usr/share/applications」内から「AtomPY35」をクリック起動し、ランチャーにアイコンが並んだらランチャーに登録しておく
画像の色も微妙に変えておくといいかもしれません。通常用のアイコンと仮想環境用のアイコンを複数つくっておけば状況に応じて使い分けも可能です。そうすれば煩わしい事前設定をせずにアイコンクリックで仮想環境でのatomが使えるようになります。
atom-scriptでのRUN方法:
Packages>Scriptの中には
Script: Run by Number (jupyter notebook用)
Run Script (python main.py/コマンドオプションなし)
Run with profile (python main.py --cuda --niter 1/コマンドオプション付き)
Stop Script
Configure Script(環境変数やコマンドオプションなどの設定)
Close Window and Stop Script
Copy Run Results
という感じでいろいろあります。
一度対象のプログラムにフォーカスを与えてから、「Configure Script」をクリックすると、
このような設定画面が現れるので、「Program Arguments:」にコマンドオプションとなる「--cuda --niter 1」を記入して右下の▶Runボタンを押せば実行できます。この場合、ターミナルは起動しなくても実行できるので比較的簡単な操作になると思います。この内容を「Save as profile」ボタンで保存しておけば、次回からボタン操作だけで実行可能となります。
一旦保存すれば、このプログラムの設定を含んだ「dcgan(名前は任意)」というボタンが生成され、Packages>Script>Run with Profile(Shift+Ctrl+Alt+B)から「dcgan」ボタンを押して▶Runボタンで実行できます。
Stop Script(Ctrl+Q)もあるので途中で終了も可能です。
platformio terminalとscriptの二つがあれば、ほぼ問題なく簡単に実行できると思います。というわけで、エディタと実行環境については思っていたようなことができるようになったので一安心です。


 1:15.80=75.8秒くらい。このサンプルでCUDA8.0と比較すると2秒くらい速くなったかもしれません。
1:15.80=75.8秒くらい。このサンプルでCUDA8.0と比較すると2秒くらい速くなったかもしれません。