前回GANについて理解を深めてみましたが、その後もGANの発展型となるACGANやInfoGANについても引き続き勉強中です。しかしながら、今回はやや方向転換して強化学習(Reinforcement Learning)について試してみました。
環境:
Ubuntu 18.04
GTX 1060
CUDA 9.0
python 3.6
tensorflow 1.9
Keras 2.1.6
Keras-rl 0.4.2
Jupyter Notebook 5.6
アルゴリズム:
強化学習には独特のアルゴリズムが使われており、ディープラーニング以前にも
・Q-Learning
・SARSA
・モンテカルロ法
などが基本としてあるようです。
その後、AlphaGOで有名となった
・DQN(Deep Q-Network)
そして、さらに改良された
・Double DQN
・Dueling DQN
・AC3
・UNREAL
・PPO
などがあるようです。日々改良されているようですが、どれがいいのかは目的によっても異なるようです。とりあえず今となってはDQNあたりが基本かと。
OpenAI:
手っ取り早く強化学習を勉強するなら
OpenAIのGYMを利用するとよさそうです。GYMには倒立振子やATARIのビデオゲームなどの教材があり、強化学習アルゴリズムを書き足せばすぐに試すことができます。
このページのインストール方法に従って必要なライブラリなどをインストールしますが、ATARIのビデオゲームを使いたい場合はcmakeも必要となるので、Ubuntuであれば一通り以下のコマンドで全てインストールしておいたほうが良さそうです。
apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb ffmpeg xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
動作チェック:
Getting Started with Gymにも書いてありますが、以下のコードで100ループ動きます(ランダムな動き)。ちなみにこのままだとJupyter Notebookでは表示(レンダリング)されないので、.pyファイルにして実行させないといけません。
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(100):
env.render()
env.step(env.action_space.sample())
env.close()
あっというまに表示が終わってしまうので以下のようにtime.sleep()でディレイを加えてみました。
import gym
import time
env = gym.make('CartPole-v0')
env.reset()
for _ in range(100):
env.render()
env.step(env.action_space.sample())
time.sleep(0.02)
env.close()
Jupyter Notebookの場合:
アニメーションをJupyter Notebook上で表示するには少し工夫が必要です。
stack overflowにもいくつか方法が書いてあります。
ATARIの場合であれば以下の方法で表示可能でした。
import gym
from IPython import display
import matplotlib.pyplot as plt
%matplotlib inline
env = gym.make('Breakout-v0')
env.reset()
img = plt.imshow(env.render(mode='rgb_array'))
for _ in range(100):
img.set_data(env.render(mode='rgb_array'))
display.display(plt.gcf())
display.clear_output(wait=True)
action = env.action_space.sample()
env.step(action)
env.close()
しかし、CartPole-v0のようなClassic controlの場合だとエラーがでてしまうので、インストールしてあるpyglet1.3.2を一旦アンインストール(pip uninstall pyglet)して、pyglet1.2.4をインストール(pip install pyglet==1.2.4)し直すといいようです(
こちらの方法)。ただこの方法だとJupyter上だけでなく別窓も開いてしまいます。そして、env.close()を最後に書き加えないと、別窓を閉じることができなくなるので要注意。
別窓だけの表示でいいのであれば(Jupyter上には表示させない)、pyglet1.2.4にダウングレードさえしておけば、以下の方法でも可能でした。
import gym
import time
env = gym.make('CartPole-v0')
env.reset()
for _ in range(100):
env.render()
env.step(env.action_space.sample())
time.sleep(0.02)
env.close()
Jupyter Notebook上に表示させる方法をいろいろ探してみましたが、別窓での表示であれば簡単そうなので、以下のKeras-RLでも別窓表示にすることにしました。
Keras-RL:
とりあえずDQNで強化学習をしたいので、どの機械学習フレームワーク(Tensorflow、Keras、Pytorchなど)を使えばいいかということですが、
Keras-RLというKeras向けの強化学習用のライブラリがあり、以下のようなアルゴリズム(
ここに書いてある)が既に搭載されており、すぐに使うことができます。
| Name | Implementation | Observation Space | Action Space |
|---|
| DQN | rl.agents.DQNAgent | discrete or continuous | discrete |
| DDPG | rl.agents.DDPGAgent | discrete or continuous | continuous |
| NAF | rl.agents.NAFAgent | discrete or continuous | continuous |
| CEM | rl.agents.CEMAgent | discrete or continuous | discrete |
| SARSA | rl.agents.SARSAAgent | discrete or continuous | discrete |
複雑なアルゴリズムをコーディングしなくても、既存の関数にパラメータを渡せば計算してくれますが、基本となるQ-Learningの仕組みはある程度理解しておいたほうがよさそうです。
Action Space欄に離散値か連続値かの違いがあるので、目的に応じて使い分けるといいと思います。
DQNを試してみる:
CartPoleのサンプル:
Keras-RLにはいくつかの
サンプルコードがあるので、
dqn_cartpole.pyを試してみることに。
Jupyter NotebookでRunさせる場合は、別窓としてアニメーションが表示されます。終了後別窓を閉じるために、最後の行にenv.close()を追加しておきます。
import numpy as np
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
ENV_NAME = 'CartPole-v0'
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.n
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
print(model.summary())
memory = SequentialMemory(limit=50000, window_length=1)
policy = BoltzmannQPolicy()
dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,
target_model_update=1e-2, policy=policy)
dqn.compile(Adam(lr=1e-3), metrics=['mae'])
dqn.fit(env, nb_steps=50000, visualize=True, verbose=2)
dqn.save_weights('dqn_{}_weights.h5f'.format(ENV_NAME), overwrite=True)
dqn.test(env, nb_episodes=5, visualize=True)
env.close()
GTX1060で、学習50000ステップ、約5分かかりました。
DQNAgentクラスに必要な項目を渡すだけなので、アルゴリズム的には超シンプルです。
CartPoleに関しては左か右に動かすだけなので、env.action_space.nは2になります。
最後のほうにあるdqn.save_weight()で学習したウェイトが外部保存されるので、次回このウェイトをつかってテストするには、以下のように書き換えることになります。
# 以下をコメントアウトして
# dqn.fit(env, nb_steps=50000, visualize=True, verbose=2)
# dqn.save_weights('dqn_{}_weights.h5f'.format(ENV_NAME), overwrite=True)
# かわりに保存したウェイトを読み込む
dqn.load_weights('dqn_{}_weights.h5f'.format(ENV_NAME))
dqn.test(env, nb_episodes=5, visualize=True)
env.close()
デフォルトでは、以下のように一回のepisodeでsteps: 200になっています。
例えばsteps: 500に変えるには、
env = gym.make("CartPole-v0")
env._max_episode_steps = 500
とすればいいようです(
ここに書いてありました)。
ATARIブロック崩しをJupyter Notebook上に表示:
もうひとつは、
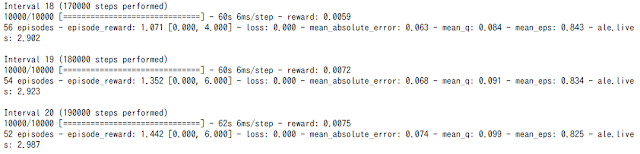
ATARIのブロック崩しのサンプルです。これは (210, 160, 3) のRGB画像を入力としてCNNを通して学習していきます。画像から判断するので、どんなゲームでもいいということになります。サンプルにある通り1750000ステップ学習するために約3時間かかりました(GTX1060)。
もともとこのサンプルは.pyファイルですが、Jupyter Notebook上に表示できるように少し手を加えてみました。サンプルは最後の方にあるdqn.test()で結果表示されますが、既存コードを見るとenv.render(mode='human')が使用されており、Jupyter Notebook上に表示するにはenv.render(mode='rgb_array')に変換する必要がありそうです。
そのため、既存の結果表示はvisualize=Falseで非表示にし、かわりに自前のCallback関数を追加することで毎ステップ画像表示させることにしました。またargparseはJupyterでは使えないので消去し、そのかわりに各変数を用意しました。
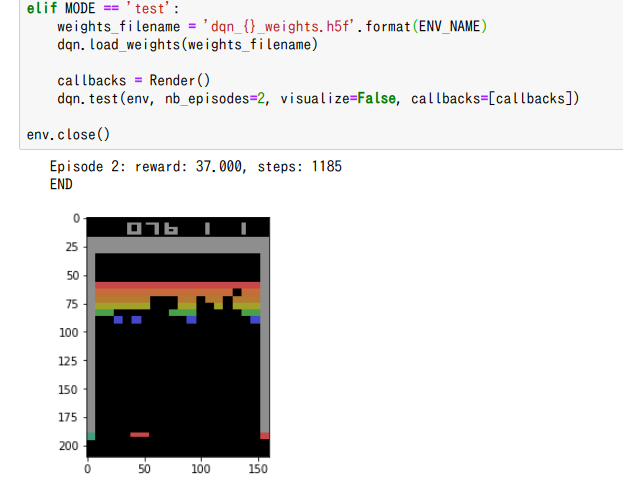
from PIL import Image
import numpy as np
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten, Convolution2D, Permute
from keras.optimizers import Adam
import keras.backend as K
from rl.agents.dqn import DQNAgent
from rl.policy import LinearAnnealedPolicy, BoltzmannQPolicy, EpsGreedyQPolicy
from rl.memory import SequentialMemory
from rl.core import Processor
from rl.callbacks import FileLogger, ModelIntervalCheckpoint
INPUT_SHAPE = (84, 84)
WINDOW_LENGTH = 4
class AtariProcessor(Processor):
def process_observation(self, observation):
assert observation.ndim == 3
img = Image.fromarray(observation)
img = img.resize(INPUT_SHAPE).convert('L')
processed_observation = np.array(img)
assert processed_observation.shape == INPUT_SHAPE
return processed_observation.astype('uint8')
def process_state_batch(self, batch):
processed_batch = batch.astype('float32') / 255.
return processed_batch
def process_reward(self, reward):
return np.clip(reward, -1., 1.)
ENV_NAME = 'BreakoutDeterministic-v4'
env = gym.make(ENV_NAME)
np.random.seed(123)
env.seed(123)
nb_actions = env.action_space.n
input_shape = (WINDOW_LENGTH,) + INPUT_SHAPE
model = Sequential()
if K.image_dim_ordering() == 'tf':
model.add(Permute((2, 3, 1), input_shape=input_shape))
elif K.image_dim_ordering() == 'th':
model.add(Permute((1, 2, 3), input_shape=input_shape))
else:
raise RuntimeError('Unknown image_dim_ordering.')
model.add(Convolution2D(32, (8, 8), strides=(4, 4)))
model.add(Activation('relu'))
model.add(Convolution2D(64, (4, 4), strides=(2, 2)))
model.add(Activation('relu'))
model.add(Convolution2D(64, (3, 3), strides=(1, 1)))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(nb_actions))
model.add(Activation('linear'))
#print(model.summary())
memory = SequentialMemory(limit=1000000, window_length=WINDOW_LENGTH)
processor = AtariProcessor()
policy = LinearAnnealedPolicy(EpsGreedyQPolicy(), attr='eps', value_max=1., value_min=.1, value_test=.05,
nb_steps=1000000)
dqn = DQNAgent(model=model, nb_actions=nb_actions, policy=policy, memory=memory,
processor=processor, nb_steps_warmup=50000, gamma=.99, target_model_update=10000,
train_interval=4, delta_clip=1.)
dqn.compile(Adam(lr=.00025), metrics=['mae'])
# コールバックとJupyter表示用モジュールのインポート
from rl.callbacks import Callback
from IPython import display
import matplotlib.pyplot as plt
%matplotlib inline
# 表示用Renderサブクラス作成(keras-rlのCallbackクラス継承)
class Render(Callback):
def on_step_end(self, step, logs={}):
plt.clf()
plt.imshow(env.render(mode='rgb_array'))
display.display(plt.gcf())
display.clear_output(wait=True)
MODE = 'train' # 'train' or 'test' 学習とテストのモード切替え
if MODE == 'train':
weights_filename = 'dqn_{}_weights.h5f'.format(ENV_NAME)
checkpoint_weights_filename = 'dqn_' + ENV_NAME + '_weights_{step}.h5f'
log_filename = 'dqn_{}_log.json'.format(ENV_NAME)
callbacks = [ModelIntervalCheckpoint(checkpoint_weights_filename, interval=250000)]
callbacks += [FileLogger(log_filename, interval=100)]
dqn.fit(env, callbacks=callbacks, nb_steps=1750000, log_interval=10000)
dqn.save_weights(weights_filename, overwrite=True)
# dqn.test(env, nb_episodes=10, visualize=False)
elif MODE == 'test':
weights_filename = 'dqn_{}_weights.h5f'.format(ENV_NAME)
dqn.load_weights(weights_filename)
# 表示用コールバック関数を適用
callbacks = Render()
plt.figure(figsize=(6,8))
dqn.test(env, nb_episodes=2, visualize=False, callbacks=[callbacks])
env.close()
元々のサンプルはargparseで'train'か'test'でモードの切り替えをしていましたが、かわりに変数MODEを用意して切り替えています(argparseの代わりに
easydictを使うといいようです)。
keras-rlのCallback関数をオーバーライドしJupyter用に表示用サブクラスをつくって、毎ステップごとにenv.render(mode='rgb_array')を呼び出して表示させています。keras-rlのCallbackクラスを見てみると、episodeやstepの前半後半のタイミングでコールバックできるようで、今回はstep後半のon_step_end()に表示機能を挿入しておきました。
この結果、一応Jupyter上には表示できるようになりましたが、plt.imshow()を使っているせいか動きが遅くなってしまいます。やはり別窓に表示させたほうがいいかもしれません。リアルタイムで表示させなくてもいいのであれば、以下の方法がいいかと。
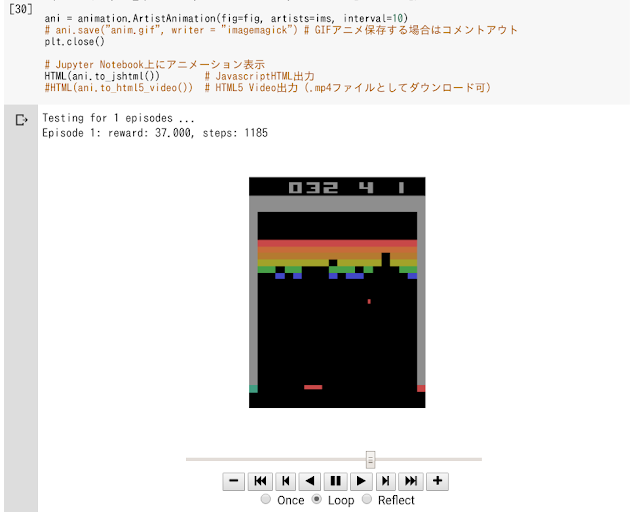
Jupyter Notebook上にアニメーション表示とGIF動画保存:
matplotlibのArtistAnimationクラスで先程のブロック崩しを表示しつつ、GIF動画として保存する方法についてです。訓練後のテスト部分を少し変えて以下のようにしてみました。
from rl.callbacks import Callback
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
%matplotlib inline
ims = [] # アニメーション用リスト
class Render(Callback):
def on_step_end(self, step, logs={}):
im = plt.imshow(env.render(mode='rgb_array'))
ims.append([im])
weights_filename = 'dqn_{}_weights.h5f'.format(ENV_NAME)
dqn.load_weights(weights_filename)
callbacks = Render()
fig = plt.figure(figsize=(4,5)) # 出力画面サイズ調整
plt.axis('off') # 目盛り、枠線なし
dqn.test(env, nb_episodes=1, visualize=False, callbacks=[callbacks])
ani = animation.ArtistAnimation(fig=fig, artists=ims, interval=10)
# ani.save("anim.gif", writer = "imagemagick") # GIFアニメ保存する場合はコメントアウト
plt.close()
# Jupyter Notebook上にアニメーション表示
HTML(ani.to_jshtml()) # JavascriptHTML出力
#HTML(ani.to_html5_video()) # HTML5 Video出力(.mp4ファイルとしてダウンロード可)
サブクラスRender()内で予め用意しておいたアニメーション用リストに毎ステップ画像を追加していき、それをあとからArtistAnimationで動画にするという手順です。ArtistAnimationを使えばすぐにGIF動画として保存もできます。
Jupyter上のアニメーション表示としては2種類あり、JavascriptHTMLは動画速度を変えて再生も可能なので便利です(上画像)。またHTML5 Video出力のほうは表示画面から.mp4として動画をダウンロードできる機能がついています。
尚、matplotlibのArtistAnimationについては以前投稿した
ここを参照して下さい。
追記:尚、このボタン付きアニメーションをWebページに埋め込むには以下。
Matplotlib Animation embed on web page:アニメーションのWebページ上への埋め込み
まとめ:
OpenAIのGYMとKeras-RLを使うことで簡単にDQNを試すことができます。DQNに渡すパラメータについて理解しておけばいいという感じです。
このほか、二足歩行モデルがあるMuJoCo、ロボットアームやハンドマニピュレータがあるRoboticsのサンプルもあります。学習させるには結構時間かかりそうなので、まだ試してはいませんが、強化学習は生成モデルとはまた違ったアプローチをしている部分が興味深いという感じ。また、強化学習と生成モデルの組み合わせもできそうなので、アルゴリズム的に面白くなりそうです。
GPUがなくても、Google Colabを使えばこの程度の訓練であれば短時間でおわるかもしれません。
関連:
Google Colabの無料GPUで強化学習訓練を試す(Keras-RL)
久保 隆宏
講談社
売り上げランキング: 115,841