前回のTitanicの続きです。
いろいろとハイパーパラメータを調節して目標としていたスコア:0.80(上位8%)を何とか超えることができましたが、どうも乱数固定が不安定で偶然出てきた結果という感じ。たぶんCUDAとともにインストールしたcuDNNのほうで乱数の固定ができていないような。まあ、それでもできるだけ固定することでわずかな誤差ですむようになってきました。以下が現在の乱数固定方法。このほかKerasのDense層のkernel_initializer、Dropoutにおいてもseedを固定しています。
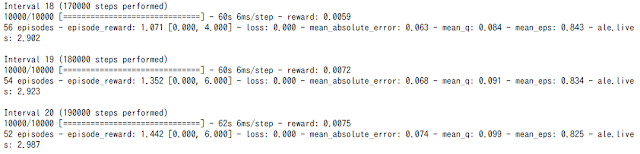
スコアをあげるための決定的な解決策はまだ出てきていないのですが、今回はKerasのEarlyStopping機能(訓練ループを自動的に止める)を使ってみました。
EarlyStoppingだけでなく、自動的に学習率を下げるReduceLROnPlateauとModelCheckpointでベストなウェイトを保存させて、その結果から予測させています。要はできるだけ自動化という方向で。
提出結果のスコアを比較していくと、隠れ層を1層にした非常にシンプルなニューラルネットのほうがいい結果が出ました。Titanicの場合はデータ数が少ないので(訓練+テスト:1309サンプル)、優れた予測モデルを構築しにくいのかもしれません。乱数の違いでもかなり結果が変わってしまうのでその辺が難しそう。
基本的にはデータをみながらの工夫はせずに、数値化したデータをそのままニューラルネットに渡して自動的に解決する方法にしています。
それぞれのデータに関しては:
Pclass:そのまま
Name:含まれるTitle(Mr/Mrsなど)を抽出し数値化(0〜17)、正規化
Sex:数値化、male:0, female:1
Age:欠損値あり(後で穴埋め)、正規化
SibSp:正規化
Parch:正規化
Ticket:削除
Fare:欠損値あり(後で穴埋め)、正規化
Cabin:欠損値も含め数値化:nan:0, C:1, E:2, G:3, D:4, A:5, B:6, F:7, T:8に変換
Embarked:欠損値あり(後で穴埋め)、数値化:S:0, C:1, Q:2
何度かスコア:0.80を超えた(上位8%)のですが、あまり当てにならないので、再度仕切り直しで以下のコード(スコア:0.78947)。
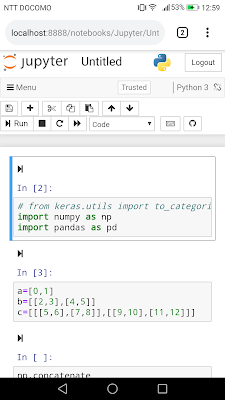
表示されない場合はこちら。
Digit Recognizer(Mnist):
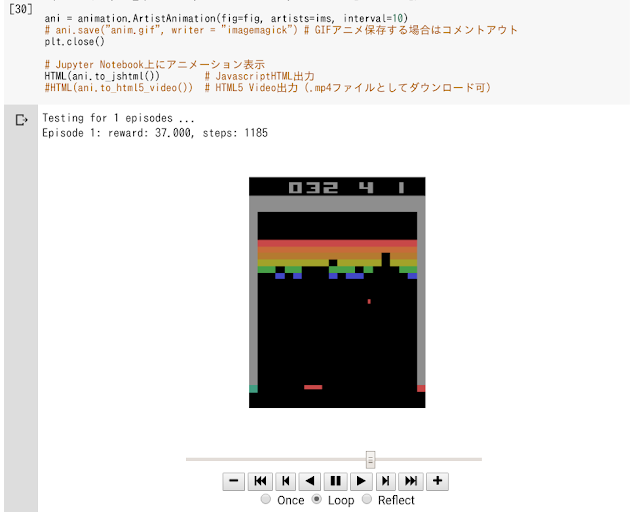
Titanicはまだまだやり続けたいのですが、1日に10回までしか提出できないので、ビギナー用のDigit Recognizerも試してみました。これはサンプルでよく使われているMnist(手書き文字)。
基本的にCNNを通して10通りの数字を分類しますが、これまで精度を上げてみるということはしたことがなかったので、どの程度できるのか今回チャレンジ。
よくあるCNNでやってみてもスコア:0.99以上にはなりました。あとは0.001でもいいのでより精度をあげるにはどうしたらいいかという感じです。
結果としては、0.99528(上位18%)まで上げることができました。以下がコード。
表示されない場合はこちら。
サンプルなどでよくあるCNNに対して層やユニット数を調整したり、BatchNormalizationやDropoutを加えてみました。最初は0.993くらいでしたが、その分やや向上しました。
この他、画像をリサイズしてKeras ApllicationsにあるXceptionやInceptionV3なども試してみましたが、それほど良い結果は得られなかったので、そんなに層を増やさなくてもよさそうです。
これもまだまだ精度をあげることはできそうなので、もう少しやり込みたいと思っています。
TGS Salt Identification Challenge:
この他、賞金ありのコンペにも試しに登録してみました。これは地質画像をもとに塩の埋蔵量を予測するコンペのようです。Kernelsには基本的なアルゴリズムがのっているので、そのままコピペしてベースラインのスコアは得られますが、そこからさらに精度をあげなければいけません。基本的に画像認識のコンペですが、セグメンテーションするためのU-net、intersection-over-union(IoU)、その離散値を連続値として計算可能にするLovasz Hinge Lossというテクニックが使われているようで難しそうです。
期限前までに完全理解することはできませんでしたが、Kernelsを読んでいるだけでも勉強になるので、難しそうでも一度参加してみて、できるところまでやってみると知見も広がってよさそうです。
いろいろとハイパーパラメータを調節して目標としていたスコア:0.80(上位8%)を何とか超えることができましたが、どうも乱数固定が不安定で偶然出てきた結果という感じ。たぶんCUDAとともにインストールしたcuDNNのほうで乱数の固定ができていないような。まあ、それでもできるだけ固定することでわずかな誤差ですむようになってきました。以下が現在の乱数固定方法。このほかKerasのDense層のkernel_initializer、Dropoutにおいてもseedを固定しています。
スコアをあげるための決定的な解決策はまだ出てきていないのですが、今回はKerasのEarlyStopping機能(訓練ループを自動的に止める)を使ってみました。
EarlyStoppingだけでなく、自動的に学習率を下げるReduceLROnPlateauとModelCheckpointでベストなウェイトを保存させて、その結果から予測させています。要はできるだけ自動化という方向で。
提出結果のスコアを比較していくと、隠れ層を1層にした非常にシンプルなニューラルネットのほうがいい結果が出ました。Titanicの場合はデータ数が少ないので(訓練+テスト:1309サンプル)、優れた予測モデルを構築しにくいのかもしれません。乱数の違いでもかなり結果が変わってしまうのでその辺が難しそう。
基本的にはデータをみながらの工夫はせずに、数値化したデータをそのままニューラルネットに渡して自動的に解決する方法にしています。
それぞれのデータに関しては:
Pclass:そのまま
Name:含まれるTitle(Mr/Mrsなど)を抽出し数値化(0〜17)、正規化
Sex:数値化、male:0, female:1
Age:欠損値あり(後で穴埋め)、正規化
SibSp:正規化
Parch:正規化
Ticket:削除
Fare:欠損値あり(後で穴埋め)、正規化
Cabin:欠損値も含め数値化:nan:0, C:1, E:2, G:3, D:4, A:5, B:6, F:7, T:8に変換
Embarked:欠損値あり(後で穴埋め)、数値化:S:0, C:1, Q:2
何度かスコア:0.80を超えた(上位8%)のですが、あまり当てにならないので、再度仕切り直しで以下のコード(スコア:0.78947)。
表示されない場合はこちら。
Digit Recognizer(Mnist):
Titanicはまだまだやり続けたいのですが、1日に10回までしか提出できないので、ビギナー用のDigit Recognizerも試してみました。これはサンプルでよく使われているMnist(手書き文字)。
基本的にCNNを通して10通りの数字を分類しますが、これまで精度を上げてみるということはしたことがなかったので、どの程度できるのか今回チャレンジ。
よくあるCNNでやってみてもスコア:0.99以上にはなりました。あとは0.001でもいいのでより精度をあげるにはどうしたらいいかという感じです。
結果としては、0.99528(上位18%)まで上げることができました。以下がコード。
表示されない場合はこちら。
サンプルなどでよくあるCNNに対して層やユニット数を調整したり、BatchNormalizationやDropoutを加えてみました。最初は0.993くらいでしたが、その分やや向上しました。
この他、画像をリサイズしてKeras ApllicationsにあるXceptionやInceptionV3なども試してみましたが、それほど良い結果は得られなかったので、そんなに層を増やさなくてもよさそうです。
これもまだまだ精度をあげることはできそうなので、もう少しやり込みたいと思っています。
TGS Salt Identification Challenge:
この他、賞金ありのコンペにも試しに登録してみました。これは地質画像をもとに塩の埋蔵量を予測するコンペのようです。Kernelsには基本的なアルゴリズムがのっているので、そのままコピペしてベースラインのスコアは得られますが、そこからさらに精度をあげなければいけません。基本的に画像認識のコンペですが、セグメンテーションするためのU-net、intersection-over-union(IoU)、その離散値を連続値として計算可能にするLovasz Hinge Lossというテクニックが使われているようで難しそうです。
期限前までに完全理解することはできませんでしたが、Kernelsを読んでいるだけでも勉強になるので、難しそうでも一度参加してみて、できるところまでやってみると知見も広がってよさそうです。

門脇 大輔 阪田 隆司 保坂 桂佑 平松 雄司
技術評論社
売り上げランキング: 363
技術評論社
売り上げランキング: 363