いつかはKaggle(機械学習コンペサイト)をやってみようと思っていましたが、今回ようやくチャレンジしてみました。練習もかねて、ビギナー向けの「
Titanic」から。
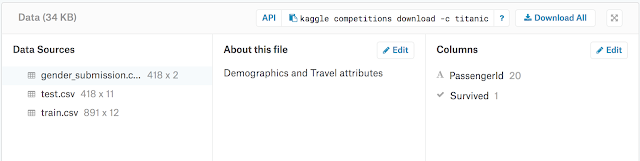
「Titanic」は訓練データを元に、テストデータの乗客者の生存確率を予想するコンペです。ビギナー向けなので締め切りはないようです。現在は1日10回まで提出できるようです(結果のスコアが分かる)。
もうすでに10000チーム以上がエントリーしてあり、100%の予想方法もあるようですが、今回はあまり難しい方法は使わず、単純にKerasでニューラルネットを組んでどのくらいの確率になるか試してみることにしました。
Googleアカウントで登録可能で、コンペにエントリーすればデータのダウンロードができます。
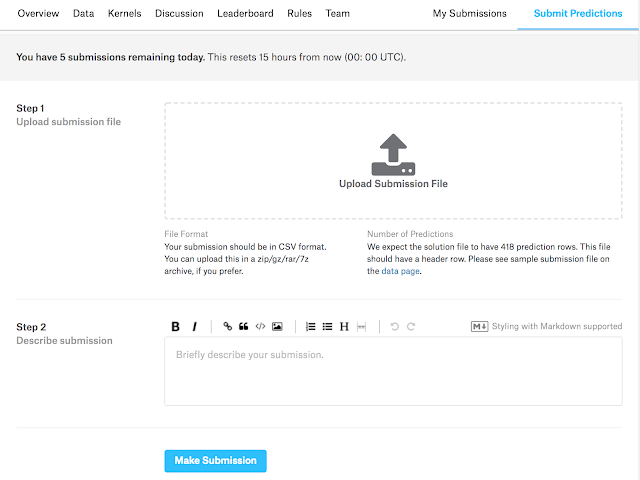
提出用ファイルの書式サンプルもあるので、それに従ってcsvファイルを書き出せばいいようです。提出は以下の画面からドラックアンドドロップでも可能(Step 1)で、すぐに結果を知ることができます。Step 2は任意のメモ欄で、パラメータの設定値などをメモしています(後で編集可)。
結果を提出すれば、以下のようにすぐにScore(右端)が出てきます。
この提出結果は0.75119なので、いまいち。
Kernels:
Kaggleには
Kernelsと呼ばれる、解析手順のアイデアやアルゴリズムが参加者によって挙げられています。これを参考にみていくと、どのようにこのデータを扱っていけばいいのかわかります。
使うデータは:
train.csv
test.csv
の二つだけで、最終的にはtest.csvの乗客者リストの生死を0/1で予想します。
データを読み込むと、
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
という項目にわかれて数値や文字列が出てきます。
直接生死に関係のないデータも含まれていますが、どの項目を重視し、あるいは捨ててしまうかはその人次第です。
しかし厄介なのは、たまにデータが抜け落ちており(欠損値)、それを捨てるか、それとも何かを手がかりに穴埋めするかも決めなくてはなりません。まずは一つずつチェックしていかなければならないのですが、Pandas(データ用ライブラリ)をつかえばこのような作業も比較的簡単にできます。
Kernelsを見ると、それぞれの項目の相関を表にしたり、事前にいろいろとデータの傾向を見ているようです。
データサイエンティストではないので、今回はこのような手続きはスキップしてKerasのニューラルネットで自動的に予測してみたいと思います。
そのためには、多少データを整理する必要があります。
・不必要と思われる項目を捨てる
・データに含まれる文字列を数値化
・必要に応じて数値を正規化/標準化
・欠損値を埋める
Pandasをそこまで使いこなしていないので、今回はPandasの勉強もかねてデータクリーニングするところから開始という感じです。
ベースライン:
一応ベースラインというものがあるようで、性別を根拠に求めると0.76555にはなるようです。その他の要素をつっこんでも0.77990が限界という人もいるようです。どうも0.80000を超えるのは難しいようで、なにかしらの工夫が必要なのかもしれません。ということで、とりあえずはベースライン以上を目指してみようかと。
門脇 大輔 阪田 隆司 保坂 桂佑 平松 雄司
技術評論社
売り上げランキング: 363
事前準備:
あとでAge, Embarked, Fareの欠損値を穴埋めするために、以下のような事前準備。
・train.csvとtest.csvを合体
・Ticketの項目を捨てる
文字列を数値へ変換:
・NameからTitle(MrやMissなど)を抜き出す
・Titleに番号を割り振る(0〜17)、合計18種類
・Sexをmale:0, female:1へ変換
・Cabinをnan:0、C:1, E:2, G:3, D:4, A:5, B:6, F:7, T:8へ変換(欠損値:0)
・Embarkedをnan:nan, S:0, C:1, Q:2へ変換(欠損値はあとで穴埋め)
これで、train.csvとtest.csvの両方を数値化(欠損値以外)完了。train.csvとtest.csvを合わせて合計1309人分のデータになります。
数値の正規化あるいは標準化:
特にAgeとFareは他の項目よりも数値が大きいので、場合によっては正規化あるいは標準化が必要かも。
データを欠損値の有無で分ける:
Age, Fare, Embarkedに欠損値があるので、これらを穴埋めするために分けておきます。そうすると、1309人中1043人分のデータが欠損値なしになります。
欠損値補完:
欠損値を穴埋めする際には
・0で埋める
・平均値で埋める
・頻度の高い数値で埋める
などいくつか方法があるようですが、今回は欠損値もニューラルネットで予想しようと思います。
ここまで準備するにも結構時間がかかりました。おかげでPandasの使い方にも慣れてきました。
Kerasで穴埋め用ニューラルネットモデルを構築:
とりあえず、層の数、ユニット数などは適当に決めて、あとから調整してみたいと思います。Embarked、Fare, Ageという欠損値の少ない順に求めてみました。
生存者予想:
nanを穴埋めしたデータを元に、train.csv(891人)からtest.csv(418人)の生存者を0/1で予想します。これもまたKerasのニューラルネットを使って予想します。
結果:
とりあえず一回目の結果としては0.71770でした。かなり低い。しかし、エラーはでないので一応アルゴリズムとしては間違ってはいなさそうなので、ここから改良していこうかと。
改良:
ニューラルネットの層をいろいろ変えてみると、層を増やしてもあまりいい結果がでないので浅くしてみました。少し改善されて0.74641。
batch_sizeをデフォルトの32から5に変えると0.75598
しかし、テストデータ418人中100人以上が間違っているということなので、ちょっとしたランダムな誤差でも数人分かわってしまいそう。このあたりになってくると、もはやゲームのハイスコア狙いのような感覚になってきます。
さらにBatchNomalizationやDropoutなども層に追加してみたり、いろいろ試してみました。しかし0.75前後という感じで0.80まではなかなか届きそうにありません。複雑にしたからといっても正解率があがるわけでもなく、精度の低いモデルにオーバーフィッティングしているだけなのかもしれません。
要素を減らして(Pclass, Sex, Age, Fare, Embarkedだけ)シンプルに計算してみると、0.77990まであがりました。ようやくベースライン。
その後、また要素は戻して、正規化で全ての数値を0.0〜1.0に変換し、比較的シンプルな層でやってみると今までのベストスコアとなる0.78947。約10000人中の3371位。半分より上に行けたのでよかったのですが、これも偶然という感じ。
random.seedによっても結果が変わりそうなので、
import tensorflow as tf
import random as rn
import os
os.environ['PYTHONHASHSEED'] = '0'
rn.seed(123)
np.random.seed(123)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
from keras import backend as K
tf.set_random_seed(123)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
で乱数を固定してみました(
Kerasの再現可能な結果)。
追記:
Dense()とDropout()のなかのkernel_initializerにも乱数の設定があるので、
kernel_initializer=keras.initializers.glorot_uniform(seed=123)
と固定してみましたが、GPUを使っているためかそれでも毎回微妙に値が異なってしまいます。cuDNNのほうも設定しないといけないのかもしれません。
まとめ:
Kaggle自体敷居が高そうですが登録や提出などは簡単で、何度も提出できるので気軽に参加できます。実際に具体的な目標(スコア)があるので工夫しがいがあります。ハマると、ゲーム感覚でハイスコアを狙うといったやりこみ癖が出てきそうです。そういう意味でも面白いかもしれません。勉強する際にサンプルコードを写経するだけでおしまいになることがありますが(動くかどうか確かめるだけ)、工夫によってスコアが変わるためいろいろ試しながら結果を比較向上していく部分がさらなる理解度を深めます。当然、データの事前処理も今まではあまりやったことはありませんでしたが、データのあり方から様々な傾向が見えてくるのも面白いと思います。
その後いろいろいじってみましたが、0.76前後をふらふらしており決定的な改善策が見当たりません。NameをTitleに変換し、さらにTitleをone-hotラベルに変換したりしましたがそれほど効果なし。欠損値をニューラルネットで予測し、その予測を元に最後の生死を予測しているので、最初の予測が間違っていれば意味がないという感じかもしれません。1日に10回まで提出することができるので何度も試しているところです。
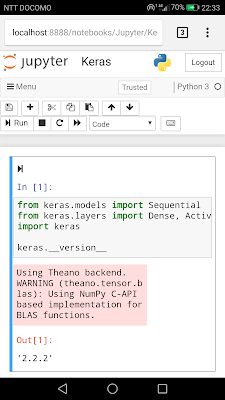
以下が、現在のコード(Jupyter Notebook)。まだベースライン前後なので、もう少し改良が必要です。