最近は、Google Colabの無料GPU(連続12時間まで)を使用して演算が可能なので、機械学習用GPUが搭載されていないパソコンでも充分機械学習の訓練などできそうです。使い方はオンラインのJupyter Notebookという感じです。
Colabスペック:
Ubuntu17.10(現在は18.04)
Intel(R) Xenon CPU @2.3GHz
13GB RAM
GPU NVIDIA Tesla K80
スペックはこんな感じ。アルゴリズムにもよりますがTesla K80がどのくらい高速なのかが気になります。自前のゲーミングノートはPascal世代のGTX1060ですが、K80はそれよりも2世代前のKepler世代のGPUのようです。
!nvidia-smiを打ち込むと以下。

このほか、機械学習に必要な基本的なライブラリはnumpy、pandas、matplotlib、Tensorflow、Kerasも含め既にインストールしてあるようです。Pytorchは入っていないのでインストールする必要があります(追記:その後Pytorchなどもインストール済みになったようです)。
ということで、前回のKeras-RL + Open AI Gym Atariの訓練(1750000ステップ)を比較してみようかと。自前のゲーミングノートGTX1060では約3時間かかりました。
インストール:
とりあえず、Keras-RLやGymなど必要なものをapt-get installやpipで前回同様にインストールする必要があります。
必要なライブラリなどはインストールできますが、再度ログインするとまたインストールし直さないといけないようです(Colab内は毎回クリアされる?)。
実行時間の比較:
以下が自前のGTX1060での訓練時のログ。これは前回Jupyter用に書き直したAtariブロック崩しの訓練です。
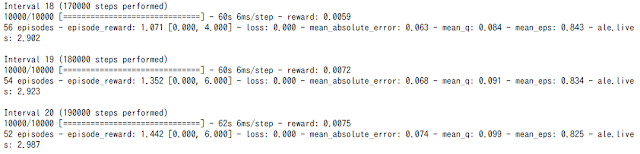 10000ステップで約60秒かかっています。訓練するには合計1750000ステップあるので、約3時間ということになります。
10000ステップで約60秒かかっています。訓練するには合計1750000ステップあるので、約3時間ということになります。
これに比べて、Google Colab(Tesla K80)の方は以下。


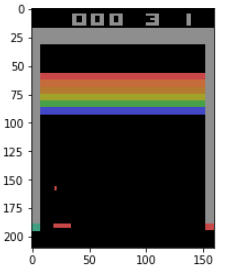
結果的には、アニメーションとして最後表示することができました。Jupyterも表示には手こずりましたが、Colabはオンラインでもあるためどうしてもリアルタイムだと遅くなってしまうようで、このようにアニメーションとして変換してしまえば問題なさそうです。アニメーションに変換する分、少しだけ(数十秒程度)余計に時間がかかりますが、特に目立った遅さではないのでこれでいけそうです。
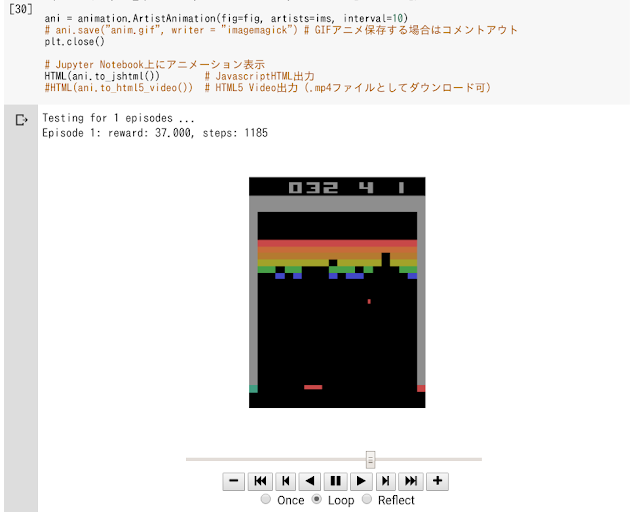 アニメーションとして保存してあるので、オンラインによるタイムラグはなく普通に速く動きます。
アニメーションとして保存してあるので、オンラインによるタイムラグはなく普通に速く動きます。
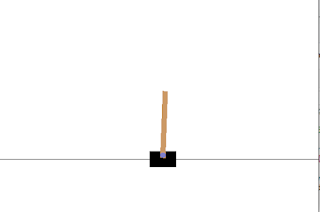
Atariの場合はこのようにColab上に表示されますが、CartPoleのようなClassic controlの場合はレンダリングの仕組みが違うためかColab上のアニメーションだけでなく別窓にも表示されてしまいます。
追記:尚、このボタン付きアニメーションをWebページに埋め込むには以下。
Matplotlib Animation embed on web page:アニメーションのWebページ上への埋め込み
まとめ:
Colabスペック:
Ubuntu17.10(現在は18.04)
Intel(R) Xenon CPU @2.3GHz
13GB RAM
GPU NVIDIA Tesla K80
スペックはこんな感じ。アルゴリズムにもよりますがTesla K80がどのくらい高速なのかが気になります。自前のゲーミングノートはPascal世代のGTX1060ですが、K80はそれよりも2世代前のKepler世代のGPUのようです。
!nvidia-smiを打ち込むと以下。

このほか、機械学習に必要な基本的なライブラリはnumpy、pandas、matplotlib、Tensorflow、Kerasも含め既にインストールしてあるようです。Pytorchは入っていないのでインストールする必要があります(追記:その後Pytorchなどもインストール済みになったようです)。
ということで、前回のKeras-RL + Open AI Gym Atariの訓練(1750000ステップ)を比較してみようかと。自前のゲーミングノートGTX1060では約3時間かかりました。
インストール:
とりあえず、Keras-RLやGymなど必要なものをapt-get installやpipで前回同様にインストールする必要があります。
!pip install gym keras-rl pyglet==1.2.4
!apt-get install -y cmake zlib1g-dev libjpeg-dev xvfb ffmpeg xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
!pip install 'gym[atari]'必要なライブラリなどはインストールできますが、再度ログインするとまたインストールし直さないといけないようです(Colab内は毎回クリアされる?)。
実行時間の比較:
以下が自前のGTX1060での訓練時のログ。これは前回Jupyter用に書き直したAtariブロック崩しの訓練です。
これに比べて、Google Colab(Tesla K80)の方は以下。
10000ステップで約108秒かかっています(意外と遅い)。
自前のゲーミングノート(GTX1060)のほうが1.8倍速いという計算になります。
とはいっても普通のMacBook(CPU演算)に比べればはるかに速いとは思います。
しかしながら、370000ステップの途中で突然ストップしてしまいました。
最後に、「Buffered data was truncated after reaching the output limit」という表示が出ています。何か出力限界に達したようで、途中停止しています。
検索してみると、Stack flowに似たような件について書いてありました。RAMかGPUのメモリをオーバーしてしまったようで、バッチサイズを少なくするか、小分けに途中経過(ウェイト)を保存しておいて再開するかなどの工夫が必要そうです。一応プログラム上ではチェックポイントを設けて250000ステップごとにウェイトを途中保存してはあります。
やはりある程度の規模になると、使用する上での工夫が必要そうです。今回の場合だと1750000ステップの訓練をさせるには概算すると5時間はかかりそうです。連続使用12時間以内で済みそうですが、それ以前にメモリなども気を遣わなければいけないということです。
ということで、処理速度を知りたかったので訓練は途中で終了。
動画表示:
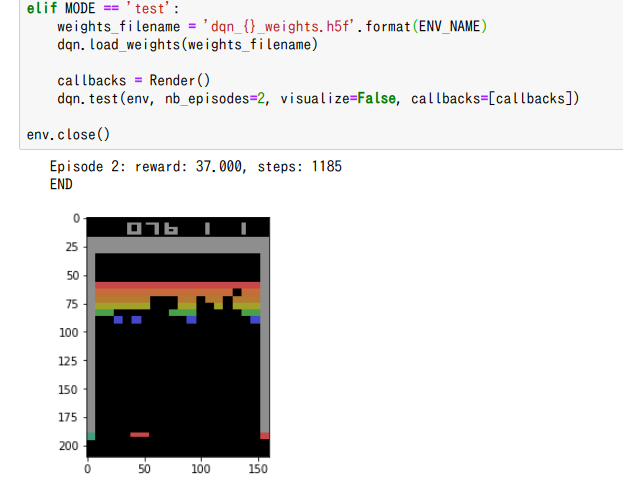
そのかわりに、以前保存しておいたウェイトを読み込んでColab上に表示できるか試してみました。
尚、外部ファイルなどを読み込ませるには以下を書き込んでランさせるとファイル選択ダイアログがでてきて、パソコンの任意の場所からファイルを読み込むことができます。
from google.colab import files
uploaded = files.upload()
前回Jupyter上で表示可能であった方法を試してみましたが、画面のちらつき、動画としての更新速度が非常に遅く、いまいちという結果。
ということから一旦出力画像を非表示にして、matplotlibのArtistAnimationに変換後表示する方法を試してみました(以下)。
from rl.callbacks import Callback
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
%matplotlib inline
ims = []
class Render(Callback):
def on_step_end(self, step, logs={}):
im = plt.imshow(env.render(mode='rgb_array'))
ims.append([im])
weights_filename = 'dqn_{}_weights.h5f'.format(ENV_NAME)
dqn.load_weights(weights_filename)
callbacks = Render()
fig = plt.figure(figsize=(4,5))
plt.axis('off')
dqn.test(env, nb_episodes=1, visualize=False, callbacks=[callbacks])
ani = animation.ArtistAnimation(fig=fig, artists=ims, interval=10)
# ani.save("anim.gif", writer = "imagemagick") # imagemagick for Ubuntu
plt.close()
HTML(ani.to_jshtml()) # JavascriptHTML output
#HTML(ani.to_html5_video()) # HTML5 Video output
結果的には、アニメーションとして最後表示することができました。Jupyterも表示には手こずりましたが、Colabはオンラインでもあるためどうしてもリアルタイムだと遅くなってしまうようで、このようにアニメーションとして変換してしまえば問題なさそうです。アニメーションに変換する分、少しだけ(数十秒程度)余計に時間がかかりますが、特に目立った遅さではないのでこれでいけそうです。
Atariの場合はこのようにColab上に表示されますが、CartPoleのようなClassic controlの場合はレンダリングの仕組みが違うためかColab上のアニメーションだけでなく別窓にも表示されてしまいます。
追記:尚、このボタン付きアニメーションをWebページに埋め込むには以下。
Matplotlib Animation embed on web page:アニメーションのWebページ上への埋め込み
まとめ:
結果的には自前のゲーミングノートGTX1060のほうが速かったのですが、数時間かかりそうな訓練の場合にはGoogle Colabのほうで処理させておき、メインのパソコンではまた別の作業をという感じで使うこともできそうなので、それなりに便利かと。
今後はこのようなGPUのクラウドサービスが主流となってくれば、機械学習をするにはわざわざゲーミングパソコンを買うまでもないかと思います。ネットだけできればいいような5万円前後のGoogle Notebookでもいいのかもしれません。

久保 隆宏
講談社
売り上げランキング: 115,841
講談社
売り上げランキング: 115,841