Courseraの機械学習コースを始めてからカリキュラム上ではWeek5ですが、面白いのでどんどん先に進んで現在はWeek7のサポートベクターマシンが終わったところです。全部で11Weekあるコースですが、このサポートベクターマシンでどうやら「教師あり学習」は最後のようで、次のWeek8からは「教師なし学習」へ移行します。
コース前半について:
これまでを振り返ると、コース前半は機械学習の基本となる線形回帰/最急降下法のアルゴリズムを学び、ロジスティック回帰、そしてニューラルネットワークと進みました。途中から過学習を防ぐ正則化という方法を学んだのが、非常に勉強になりました。

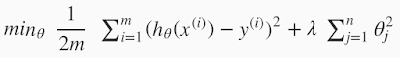
自動的に過学習を防ぐ効果があるようで、アルゴリズムとしては一層賢くなったということです。
このコース以前に独学で機械学習を勉強していましたが、ネット検索などすると最初の式は基本の式なので見つけられたのですが、さらなる応用として正則化の式を追加するところまでは、なかなか気づきませんでした。というか、初心者にとっては最初の基本の式だけでも充分勉強になっているので、そこで終わりにしてしまいがちです。やはりこのようなことは独学というよりはコースを通して徐々に蓄積していくのがいいと思いました。
しかしながら、登場してくる式はどんどん複雑になっていきます。独学だとこのような複雑な式が出てくると、先へ進むことをためらってしまいますが、コースの中では何回も登場してくるし、きちんと中身を説明してくれるので理解も深まりつつ、このような複雑な式を見ても驚かなくなってきました。

例えばこれ↑、上の式は正則化されたロジスティック回帰の式。一見複雑に見えますが、ロジスティック回帰でどのように計算しているのかわかっていれば(それほど難しい計算ではない)、特に問題ありません。しかし、その下はWeek4〜5のニューラルネットワークに出て来る式です(相当複雑)。ニューラルネットワークかつ出力が複数あるためΣがたくさん重なっています。これなんかは、独学している最中にネット検索して登場してきたら、大抵の人は見ただけで諦めてしまうと思います。確かにバックプロパゲーションの式も複雑だし、プログラミングで実装する際も面倒です。しかし、一旦プログラミングコードに置き換えると、どのような順番でこの複雑な式が計算されていくかが分かるので、より理解が深まります。このWeek5が前半で最も大変なところかもしれません。個人的にはプログラミングコードに置き換えることで理解が深まりましたが、プログラミングが苦手だとかなり苦戦するかもしれません。
以下が、Week5のバックプロパゲーションのプログラミング課題内のコード。
 それぞれの変数を用意し、順を追って計算してくので理解が深まります。式と言っても変数には行列が代入されているので、行列のマトリクスが食い違うとエラーがでてしまいます。しかもニューラルネットワークの場合、バイアス項を追加したり、削除して計算しなければいけない箇所があり、そのまま行列を代入して計算すればいいというわけではないところが面倒です。このコードを実装するために数時間試行錯誤しましたが、その分覚えてしまったという感じです。
それぞれの変数を用意し、順を追って計算してくので理解が深まります。式と言っても変数には行列が代入されているので、行列のマトリクスが食い違うとエラーがでてしまいます。しかもニューラルネットワークの場合、バイアス項を追加したり、削除して計算しなければいけない箇所があり、そのまま行列を代入して計算すればいいというわけではないところが面倒です。このコードを実装するために数時間試行錯誤しましたが、その分覚えてしまったという感じです。
ちなみにプログラミング課題は、Atomエディタを使ってやっています。Octaveの課題ファイル、課題説明のPDF、そしてターミナルを分割した画面で同時に開けるので便利です。
Week7/サポートベクターマシン:
カリキュラムの予定より2週間ほど先回りして、教師あり学習の最後であるサポートベクターマシンです。
 以前にサポートベクターマシンは少し見たことはあり、マージンを持った決定境界のある分類アルゴリズムという程度の理解でした。あまり線形回帰やロジスティック回帰との区別もできなかったので、特に面白そうとは思っていなかったのですが(直線で区切ることしかできないと思っていた)、サポートベクターマシンにカーネル法が加わると強力なアルゴリズムになるらしく、かなり使えるということらしいです。
以前にサポートベクターマシンは少し見たことはあり、マージンを持った決定境界のある分類アルゴリズムという程度の理解でした。あまり線形回帰やロジスティック回帰との区別もできなかったので、特に面白そうとは思っていなかったのですが(直線で区切ることしかできないと思っていた)、サポートベクターマシンにカーネル法が加わると強力なアルゴリズムになるらしく、かなり使えるということらしいです。
しかし、前半の数学的な説明を聞いていると複雑な仕組みとなっているようだったので、先に進む前に、いろいろネットを通して調べたりしてみました。
どうやら数学的にきちんと理解しようとすると、ラグランジュの未定乗数法というさらに難しい概念が出てきて、それによってどのような仕組みになっているのかの理解は深まるのかもしれませんが、あまり理論的な部分に首をつっこむと時間ばかりとられるので、理論的な理解よりも、どのようなことができるのかというような使用法のほうに焦点をあわせていくことにしました。
UdacityのIntro to Machine Learningのサポートベクターマシン:
サポートベクターマシンの数学的な説明によって難解なイメージを持ってしまったため、ほかのコースではどのように教えているのだろうと、以前少しだけ受講してみたUdacityのIntro to Machine Learningのサポートベクターマシンの部分を見てみました。このコースを見るのはもうやめようと思っていましたが、今回は案外役に立ちました。
Lesson3がSVM(サポートベクターマシン)です。このコースのほうが初心者向けという感じです。実際コース内では、ミニクイズやPythonによるプログラミング課題も同時にこなしていきます。

コース前半について:
これまでを振り返ると、コース前半は機械学習の基本となる線形回帰/最急降下法のアルゴリズムを学び、ロジスティック回帰、そしてニューラルネットワークと進みました。途中から過学習を防ぐ正則化という方法を学んだのが、非常に勉強になりました。

基本となる最急降下法の式は上↑のようになりますが(最初この式を見たとき、Σが式中にあるので難しそうなイメージでしたが)、以下の式のように上の式の最後の部分にλの式を追加すると(更に複雑になる)、

自動的に過学習を防ぐ効果があるようで、アルゴリズムとしては一層賢くなったということです。
このコース以前に独学で機械学習を勉強していましたが、ネット検索などすると最初の式は基本の式なので見つけられたのですが、さらなる応用として正則化の式を追加するところまでは、なかなか気づきませんでした。というか、初心者にとっては最初の基本の式だけでも充分勉強になっているので、そこで終わりにしてしまいがちです。やはりこのようなことは独学というよりはコースを通して徐々に蓄積していくのがいいと思いました。
しかしながら、登場してくる式はどんどん複雑になっていきます。独学だとこのような複雑な式が出てくると、先へ進むことをためらってしまいますが、コースの中では何回も登場してくるし、きちんと中身を説明してくれるので理解も深まりつつ、このような複雑な式を見ても驚かなくなってきました。

以下が、Week5のバックプロパゲーションのプログラミング課題内のコード。

ちなみにプログラミング課題は、Atomエディタを使ってやっています。Octaveの課題ファイル、課題説明のPDF、そしてターミナルを分割した画面で同時に開けるので便利です。
Week7/サポートベクターマシン:
カリキュラムの予定より2週間ほど先回りして、教師あり学習の最後であるサポートベクターマシンです。

しかし、前半の数学的な説明を聞いていると複雑な仕組みとなっているようだったので、先に進む前に、いろいろネットを通して調べたりしてみました。
どうやら数学的にきちんと理解しようとすると、ラグランジュの未定乗数法というさらに難しい概念が出てきて、それによってどのような仕組みになっているのかの理解は深まるのかもしれませんが、あまり理論的な部分に首をつっこむと時間ばかりとられるので、理論的な理解よりも、どのようなことができるのかというような使用法のほうに焦点をあわせていくことにしました。
UdacityのIntro to Machine Learningのサポートベクターマシン:
サポートベクターマシンの数学的な説明によって難解なイメージを持ってしまったため、ほかのコースではどのように教えているのだろうと、以前少しだけ受講してみたUdacityのIntro to Machine Learningのサポートベクターマシンの部分を見てみました。このコースを見るのはもうやめようと思っていましたが、今回は案外役に立ちました。
プログラミング課題では、Pythonの機械学習ライブラリであるscikit-learnを用います。プログラミングでは予め用意されたコードに少しだけ書き足すという程度なので、それほどコーディングの勉強にはならないのですが、このライブラリでどのようなことができるのかということを試したりするので、なにができるのかということは分かってきます。当然SVM用の関数も用意されているので、わざわざフルスクラッチでコーディングする必要はありません。いくつかパラメータを渡してあげることで、すぐにカーネル法を使うこともできます。

カーネル法を使うと、こんな感じ↑で複数の領域を曲線で区切ることもできます。パラメータによって、アンダーフィッティング/オーバーフィッティングも簡単に調整できます。
Courseraの授業内でも言ってましたが、数学的な理解を深めなくてもライブラリを使いこなすことはできるので、より実践的な方向性を求めているならば、数学的な原理を追求するよりも応用のスキルを身につけたほうがいいと思います。使用例を見れば、どのようなことができるのかというイメージが湧くので、あとはどこを調整すればいいのかということもわかりやすくなってきます。
ということで、このUdacityのIntro to Machine LearningのLesson3/SVMを一通り見て、大体の概要はつかめたのでよかったです。
再度、Courseraのサポートベクターマシン:
大体のイメージはつかめたので、再度Courseraのコースに戻り、カーネル法から勉強再開しました。カーネル法によってサポートベクターマシンが複雑な分類も可能になるので、これまでの分類アルゴリズムとは違って面白く感じてきました。
しかし、この辺になると、フルスクラッチでSVMを実装するというよりも、便利な既存ライブラリを使って何が可能か、このパラメータをいじるとどうなるのかという、どちらかというと実践的な内容に方向性が変わってきたと言う感じです。
最終的なプログラミング課題もスパムメール判定アルゴリズムについてであり、SVMの仕組みについてというよりも、SVMを使ってどのようにメールの文章をアルゴリズムに組み込んでいくのかという内容でした。最初は難解なイメージがあったので、プログラミング課題も大変なのかと思ったら、案外そうでもなくてあっさり終わってしまいました。
まとめ:
おそらく、Week5のバックプロパゲーションまでが原理的な勉強で、その後は実装したアルゴリズムをどうやって評価するのか、あるいはより良いパラメータの探し方や検証の仕方など、実際に使うことができるようにするために必要な知識やスキルというものへ移行して行った感じです。当然より高度なアルゴリズムを開発することも大事ですが、その使い方や評価も同時にできなければ、有効な結果を出すことができないので、実践的側面についても学ぶことができたのはよかったと思います。
次のWeek8からは教師なし学習なので、さらに面白くなりそうです。やはり、教師あり学習は、答え合わせができるので、その分学習もしやすいアルゴリズムというイメージですが、答え合わせができない教師なし学習によるアルゴリズムにおいて、どうやって答えを見つけていくのか不思議な感じがします。
機械学習を学んでからは数学に対するイメージが変わりました。いままでは数学と言えば、便利な公式があって、長さを知りたければ三平方の定理を使ったり三角関数を使ったりと、求めたいものに応じて公式を使い分けていただけでした。このような計算方法はどちらかというと静的であって、最急降下法のようなコンピュータのループ演算によって動的に答えを導きだす方法を知ったときはかなり新鮮でした。さらには、公式に当てはめて計算するというより、世の中に存在するいろんな数式を部品のように自由自在に組み合わせて、面白い挙動を示すアルゴリズムをつくることもできるということもわかりました。どうしても数学は、これを求めるためにはこの公式が必要という感じで手続きそのものも規則的なイメージがありましたが、優れたアルゴリズムをつくる上でも、もっと自由に計算していいというのが分かってきて、数学もかなり創造的なんだと最近感じでいます。















