引き続きDeep Learningの画像生成GAN(Generative Adversarial Network)について、いろいろ試しています。最近では3DデータのGANもあるようです。この
The GAN Zoo というところにはいろんなGANがのっていますが、とりあえずは、鮮明な合成画像をつくりだすことが可能な
DCGAN 、そして一方の属性を他の属性へ合成する
Disco GAN などを試そうと思っています。
GANの前にVAEの学習:
GANを勉強するためには、その前に
VAE(Variational Autoencoder) を理解したほうがいいということで、ここしばらくはVAEを勉強していました。VAEを学ぶ前には、Autoencoderというアルゴリズムがあり、それは簡単な仕組みなのですが、VAEになるとかなり難しい概念が登場してきます。
・Autoencoder:簡単なエンコード/デコードのアルゴリズム
・VAE:正規分布、ベイズ推定、変分ベイズ、KLダイバージェンスなどの知識が必要
VAEの場合、途中で確率分布に置き換えるという手法が特に難解だったのですが、そういう手法をとることで、デコード(生成や再現)が可能となるというのは、なかなかの発見でした。その他の生成モデルにおいても確率分布を使うことがあるので、このあたりの手法はある程度理解しておいたほうが後々役に立ちそうです。
ということでVAEも面白いのですが、そろそろGANに移行しようということで、いろいろサンプルを物色していました。主にはTensorflowを使っていますが、最近のGANのソースは
Pytorch で書かれているものも多く、
Keras なども含め比較的シンプルに書けるライブラリが増えてきたようです。
tflearn というTensorflowをシンプルにしたライブラリもあり、かなり短いコードで書くことができます。
tflearnでDCGANを試す:
tflearnのexamplesにある
dcganのサンプル はたった138行しかないので試してみました。しかし、このサンプルはこのままだとエラーがでるようで、
この訂正のページ (dcganの欄)にあるように102、103、110行目の最後に「,2」を追加する必要があります。訂正すれば動くのですが、このdcganのサンプルも相変わらずMNIST(手書き文字)であり結果はあまり面白くはないです。せっかく画像生成のアルゴリズムなので、もう少し面白い画像を使ったほうがいいのですが、気の利いたデータセットがないというのが現状でしょうか。前回Udemyのコースで試したCelebA(セレブ顔画像) ならまだましかもしれません。
データセットについて:
他にデータセットはないかと探してみましたが、
こちら に詳しく書かれています。
MNIST:手書き数字、70000(Tr:55000/Vl:5000/Te10000)、白黒、28x28px、
CelebA :セレブ顔、202600、カラー、178x218px
CIFAR-10 :10クラス、60000(10x6000)、カラー、32x32px
CIFAR-100 :100クラス、60000(100x600)、カラー、32x32px
Fashion MNIST :洋服/靴/鞄など10クラス、60000+10000、グレー、28x28px
ImageNet:未登録のため画像ダウンロードはまだ使えない(そのうち)
Google/Open Images:膨大すぎてつかいにくそう(そのうち)
すぐにダウンロードして使えそうなのは、それほどない。プログラムを書いてWebからスクレイピングする方法もあるかもしれないけれども、数万単位でのイメージが必要そうなので、個人で集めるには面倒。いまのうちからコツコツ集めておけば、かなりの価値になるにかもしれないけれども。
以下はCIFAR-10(10種類のクラス)。
CIFAR-100をダウンロード:
ということから、今回はなんとなく無難なCIFAR-100を試してみることに。
こちらの記事 を参考にスクリプトを書いてみました。データはCIFARのサイトにあるCIFAR-100 Python versionをダウンロードしました。解凍すると、そのまま画像が出てくるわけではなく、各画像はすでに1次元のデータになっているようです。ニューラルネットに画像データをインプットするならそのまま1次元がいいとは思いますが、必要に応じて2次元(3チャンネルカラー)に変換したり、あるいはグレースケールに落としたりすることもあります。
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import os
def unpickle(file):
import cPickle
with open(file, 'rb') as fo:
dict = cPickle.load(fo)
return dict
def get_cifar100(folder):
train_fname = os.path.join(folder,'train')
test_fname = os.path.join(folder,'test')
data_dict = unpickle(train_fname)
train_data = data_dict['data']
train_fine_labels = data_dict['fine_labels']
train_coarse_labels = data_dict['coarse_labels']
data_dict = unpickle(test_fname)
test_data = data_dict['data']
test_fine_labels = data_dict['fine_labels']
test_coarse_labels = data_dict['coarse_labels']
bm = unpickle(os.path.join(folder, 'meta'))
clabel_names = bm['coarse_label_names']
flabel_names = bm['fine_label_names']
return train_data, np.array(train_coarse_labels), np.array(train_fine_labels), test_data, np.array(test_coarse_labels), np.array(test_fine_labels), clabel_names, flabel_names
def get_images(name):
tr_data100, tr_clabels100, tr_flabels100, te_data100, te_clabels100, te_flabels100, clabel_names100, flabel_names100 = get_cifar100("../large_files/cifar-100-python")
#print(clabel_names100)
images = []
for i in range(len(tr_flabels100)):
if tr_flabels100[i] == flabel_names100.index(name):
#im = tr_data100[i].reshape(3,32,32).transpose(1, 2, 0) #(32,32,3)
im = tr_data100[i].reshape(3,32,32)
im = im[0]/3.0 + im[1]/3.0 + im[2]/3.0
images.append(im)
return images
これをutil.pyなどと保存して、先程のtflearnの
dcganサンプル で使ってみました。ある特定のジャンルを学習できるように、ラベル名に対応した番号のみを読み込むということにしています。元画像はカラーですがグレースケールに変換しています。
get_images('bicycle')
とすれば、自転車の画像だけ合計500個読み込むということです。
ちなみにCIFAR-100の場合、clabel_names100という20種類の大きなクラスとflabel_names100というさらに細かい100種類のクラスに分かれているようです。
flabel_names100[9] = 'bicycle'
という関係なので、
tr_data100[9]
が、ある自転車の画像となります。画像はランダムに配置されているようで、forループである特定の種類の画像を抜き出すようにしています。
以下が、CIFAR-100のクラス。
clabel_names100 = [
'aquatic_mammals', 'fish',
'flowers', 'food_containers',
'fruit_and_vegetables', 'household_electrical_devices',
'household_furniture', 'insects',
'large_carnivores', 'large_man-made_outdoor_things',
'large_natural_outdoor_scenes', 'large_omnivores_and_herbivores',
'medium_mammals', 'non-insect_invertebrates',
'people', 'reptiles',
'small_mammals', 'trees',
'vehicles_1', 'vehicles_2']
flabel_names100 = [
'apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle', 'bicycle', 'bottle',
'bowl', 'boy', 'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle', 'caterpillar', 'cattle',
'chair', 'chimpanzee', 'clock', 'cloud', 'cockroach', 'couch', 'crab', 'crocodile', 'cup', 'dinosaur',
'dolphin', 'elephant', 'flatfish', 'forest', 'fox', 'girl', 'hamster', 'house', 'kangaroo', 'keyboard',
'lamp', 'lawn_mower', 'leopard', 'lion', 'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain',
'mouse', 'mushroom', 'oak_tree', 'orange', 'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck','pine_tree',
'plain', 'plate', 'poppy', 'porcupine', 'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket',
'rose', 'sea', 'seal', 'shark', 'shrew', 'skunk', 'skyscraper', 'snail', 'snake', 'spider',
'squirrel', 'streetcar', 'sunflower', 'sweet_pepper', 'table', 'tank', 'telephone', 'television','tiger',
'tractor',
'train', 'trout', 'tulip', 'turtle', 'wardrobe', 'whale', 'willow_tree', 'wolf', 'woman', 'worm']
全体では60000イメージあるのですが、一つのクラス(種類)は500個のイメージしかなく、Disco GANのように何か特定のジャンルを学習させようとすると画像数が足りなさすぎというのを後から気づきました。CIFAR-100はいろんな種類の画像があるかわりに画像数が少ない。CIFAR-10なら一つの種類で画像が6000あるので、まだましかもしれませんが、10種類しかジャンルがない(選びたいジャンルがない)。というわけで、思い描いているようなものを学習させて、それらを合成させたいということがなかなかできません。あくまで、すでに用意されている範囲でのジャンルを使って、試すということくらいしかできないというのが現状。
Deep Learningを実験していくには、数学を含めたアルゴリズムの勉強だけでなく(特に
ベイズ推定 をつかった確率論的モデルなどが面白そう/今後より重要になっていくらしい)、データセットについても揃えなければいけないという難問があり、さらにはこのような画像生成をするなら、GPUマシンも必要という感じで、やはり先に進めば進むほど敷居が高くなってきます。段々面白くはなってきたけれども、色々面倒なことも増えてきました。
VIDEO
ベイズ推定については、この動画も面白い。今までの固定的な考え方が変わりそうな感じです。
Posted with
Amakuri at 2017.10.29
須山 敦志
講談社
販売価格 ¥3,024
Posted with
Amakuri at 2017.10.29
中島 伸一
講談社
販売価格 ¥3,024
 約20万枚の画像(64x64px)を使って6330回動かしてみた結果です。これらの顔画像はDCGANによって生成されたものであり、実在の顔ではありません。結果は前回と代わり映えしないですが、GPUによる圧倒的な速さで、今後このような画像生成も時間をかけずにいろいろ試していけそうです。
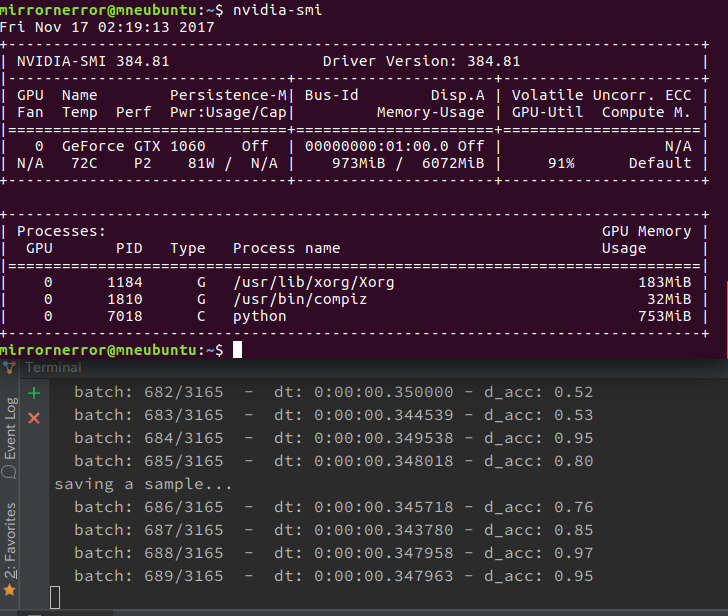
約20万枚の画像(64x64px)を使って6330回動かしてみた結果です。これらの顔画像はDCGANによって生成されたものであり、実在の顔ではありません。結果は前回と代わり映えしないですが、GPUによる圧倒的な速さで、今後このような画像生成も時間をかけずにいろいろ試していけそうです。 こちらは、実行中にnvidia-smiでGPUの状況を出力したものです。GPU稼働率91%ということでしょうか?
こちらは、実行中にnvidia-smiでGPUの状況を出力したものです。GPU稼働率91%ということでしょうか? ここではGPU稼働率98%になっています。
ここではGPU稼働率98%になっています。 GPU出力はAuto/Adaptive/Prefer Maximum Performanceがあるようです。いつのまにかAdaptiveが選択されていました。試しにAutoに変えてみようかと。
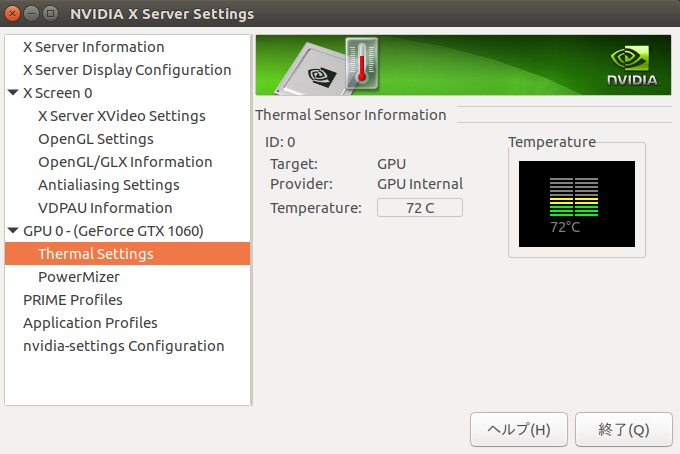
GPU出力はAuto/Adaptive/Prefer Maximum Performanceがあるようです。いつのまにかAdaptiveが選択されていました。試しにAutoに変えてみようかと。 実行中はGPUの温度が72度前後でした。普段は50度前後なので、そこそこ熱くなっているようです。そのためファンはほぼ全開で動いていました。
実行中はGPUの温度が72度前後でした。普段は50度前後なので、そこそこ熱くなっているようです。そのためファンはほぼ全開で動いていました。