Deep Learningで学習する際に、現在使用しているMacbook Pro(2014年製)だとCPU計算のため数十時間とか普通にかかってしまいます。あまりにも効率が悪いので、GPU搭載のパソコンの必要性が高くなってきました。GPUパソコンを新規購入せずにクラウド(有料)で計算させる方法もありますが、外付けGPUという手段もあるようです。性能的な面から言えばデスクトップ型のGPUパソコンが一番効率良さそうですが、個人的には持ち歩きをするために、幾分スペックが落ちてもGPUノート型(ゲーミングノートパソコン)がいいかなと。
Deep Learningを実験していくには、数学を含めたアルゴリズムの勉強だけでなく(特にベイズ推定をつかった確率論的モデルなどが面白そう/今後より重要になっていくらしい)、データセットについても揃えなければいけないという難問があり、さらにはこのような画像生成をするなら、GPUマシンも必要という感じで、やはり先に進めば進むほど敷居が高くなってきます。段々面白くはなってきたけれども、色々面倒なことも増えてきました。
見比べると確かに向上しているような気もしますが、やや絵画っぽい作風にも見えます。この出力結果が面白いかどうかというよりも、GANの特長である二つのニューラルネットが互いに競い合うことで生成されるアルゴリズムの仕組みが面白いです。この手の画像生成の技術は次々と新しいのがでているので日々見逃せないという感じです(The GAN Zoo)。
Coursera コース1(4週):Neural Network and Deep Learningを開始
ということで、早速Courseraのこのコースを開始してみました。Week1は概要やこのコース自体の説明などで、特にプログラミングするなどの技術的なことはしませんでした。前回受講したMachine Learningコースとも内容が重なる部分もあるので、さらっと聞き流す感じでも大丈夫でした。同じように動画途中でのミニクイズがあり、Week最後にあるクイズは前回のコースでは5問でしたが10問(8問以上正解で合格)に増えていました。このクイズが結構難しくて、というのも英語なのでよく読まないとすぐに間違ってしまいます。前回のコースでも何回もやり直しました。
Week2からようやく実際的な内容に入っていくわけですが、前回のMachine Learningコースで学んだ内容と重なっている部分も多いという感じです。
ただ今回のコースはPython(Jupyter Notebook)、Numpyを使うので、それに合うアルゴリズムになっているのか微妙に違います。個人的には、Numpyよりも前回使っていたOctave言語のほうがシンプルで分かりやすいという印象でしたが、Numpyにも慣れるという意味で前回の復習も兼ねてすすめてみました。前回のコースのおかげか、Week2まではあっさり終わってしまい、残すところWeek3とWeek4だけです。
Week3からより本格的にニューラルネットワークの勉強です。それと同時にNumpyに則した行列計算方法や偏微分の説明が何回も出てきます。Week最後のプログラミング課題はブラウザ上でJupyter Notebookを使うので、以前のコースよりも便利になったという感じです。相変わらず数行を穴埋めしていく課題なので難しくないのですが、PythonやNumpyには慣れていないと記述の仕方がわかならくなるときもあります。そうやってNumpyにも慣れていきつつ、Week4に入ってしまいました。
この週で最後、複数のレイヤーを持つニューラルネットワークの実装です。相変わらずバックプロパゲーションは面倒で、前回のコースでもやったので原理は分かるのですが、複数層に対応できる一般化した式をいざNumpyで実装となるとけっこう大変でした。前回のコースでもフォワードプロパゲーションとバックプロパゲーションを復習しておきたいと思っていたので、今回Numpyで試してみてまたさらに理解が深まったという感じです。
Week4の最後のプログラミング課題は、一旦計算した値をキャッシュに記憶させておいたり、連想配列のようなディクショナリに変数を登録しておいたりというテクニックを多用しているので、このへんが慣れなくてForumを覗いてなんとか実装することができました。Numpyにおける、forループを使わない行列計算の方法、ブロードキャストなども慣れていないので、Deep Learningの内容というよりはNumpyについてももう少し勉強が必要という感じです。
コース1(4週):Neural Network and Deep Learning終了
無料期間(1週間)ということで試しに受講してみましたが、3日くらいで終わってしまいました。前回のMachine Learningコースを受講していれば、Week1と2は聞き流す程度でもいいと思います。実質、Week3とWeek4をやればいいのかもしれません(それぞれ1日ずつ)。
 約20万枚の画像(64x64px)を使って6330回動かしてみた結果です。これらの顔画像はDCGANによって生成されたものであり、実在の顔ではありません。結果は前回と代わり映えしないですが、GPUによる圧倒的な速さで、今後このような画像生成も時間をかけずにいろいろ試していけそうです。
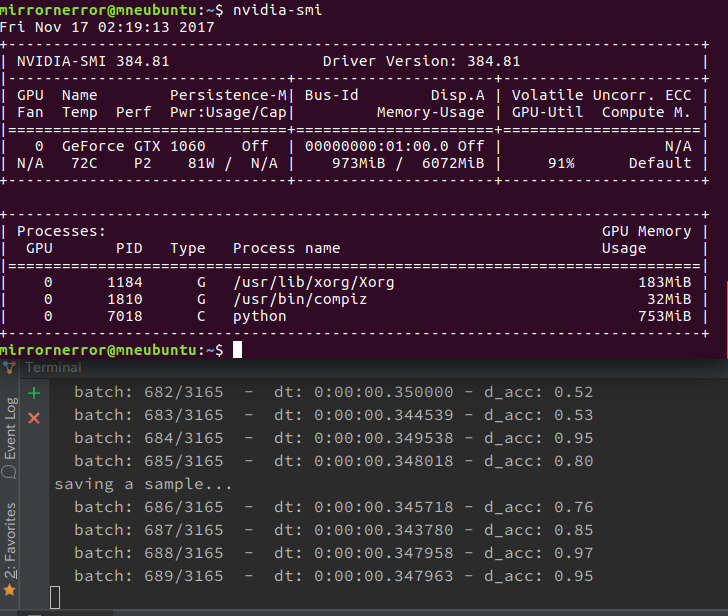
約20万枚の画像(64x64px)を使って6330回動かしてみた結果です。これらの顔画像はDCGANによって生成されたものであり、実在の顔ではありません。結果は前回と代わり映えしないですが、GPUによる圧倒的な速さで、今後このような画像生成も時間をかけずにいろいろ試していけそうです。 こちらは、実行中にnvidia-smiでGPUの状況を出力したものです。GPU稼働率91%ということでしょうか?
こちらは、実行中にnvidia-smiでGPUの状況を出力したものです。GPU稼働率91%ということでしょうか? ここではGPU稼働率98%になっています。
ここではGPU稼働率98%になっています。 GPU出力はAuto/Adaptive/Prefer Maximum Performanceがあるようです。いつのまにかAdaptiveが選択されていました。試しにAutoに変えてみようかと。
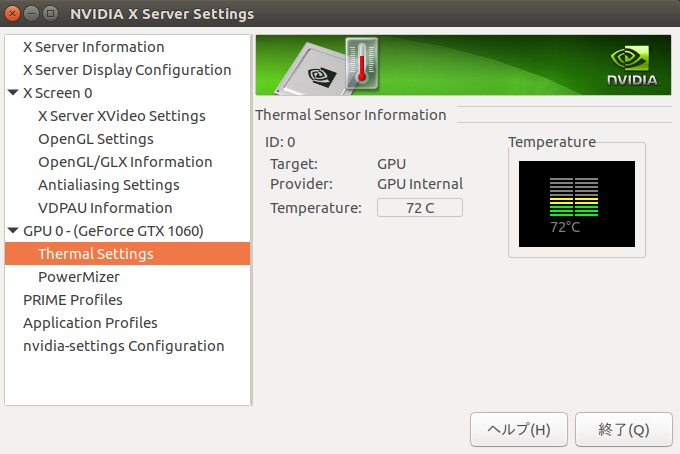
GPU出力はAuto/Adaptive/Prefer Maximum Performanceがあるようです。いつのまにかAdaptiveが選択されていました。試しにAutoに変えてみようかと。 実行中はGPUの温度が72度前後でした。普段は50度前後なので、そこそこ熱くなっているようです。そのためファンはほぼ全開で動いていました。
実行中はGPUの温度が72度前後でした。普段は50度前後なので、そこそこ熱くなっているようです。そのためファンはほぼ全開で動いていました。