前回VAE(Variational Autoencoder)を試して見たので、今回はDCGAN(Deep Convolutional Generative Adversarial Networks)をKerasで実装しつつ理解を深めたいと思います。使用データはMNISTです。
元々GANによる画像生成に興味があったのですが、約10ヶ月前にサンプルを試したときには、二つの敵対するネットワークによって画像生成するという大まかな流れしか理解できませんでした。
チュートリアルなどでは、
・Autoencoder(AE)
・Variational Autoencoder(VAE)
・Generative Adversarial Networks(GAN)
という順番で説明されていることが多く、VAE(潜在空間、ベイズ推定、KLダイバージェンスなど)を理解しないことにはGANを理解することも難しいかなと勝手に思っていましたが、そもそもAEとVAEも大きく異なるしGANもまた別のアルゴリズムという感じで、基本のAEが分かればGANを理解することはできそうです。
GANの派生型はいろいろありますが、とりあえず今回はDCGANを理解しようと思います。
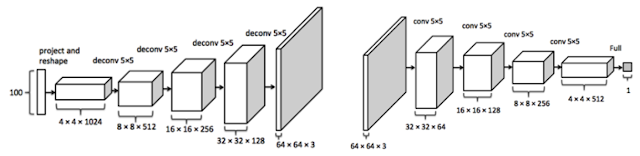
上の画像はDCGANの構造で、左半分がGeneratorで右半分がDiscriminatorです。最終的にはGenerator層の右端(上画像中央:64x64x3)に画像が生成されます。
まずGeneratorで画像生成する前に、Discriminatorの左端から訓練画像を入力してDiscriminatorだけを教師あり学習します。その後、GeneratorとDiscriminatorを連結させたネットワークで教師あり学習させます。このときDiscriminatorの学習を停止させておいてGeneratorだけが学習するようにします。そうすると既に学習されているDiscriminatorを利用しながらGeneratorだけが学習し、その結果として画像が生成されます。この交互に学習させる手順がわかりにくいので難しく見えるのかもしれません。
GeneratorはAEやVAEのdecoder層だけで構成されている感じで、最初のノイズ画像はVAEで言う潜在空間と呼びますが、途中でReparameterization TrickやKLダイバージェンスなどの複雑な計算を使うこともないので、潜在空間というよりは単なるノイズ画像(np.random.normalで生成)と捉えたほうがよさそうです。
GANの訓練の特長:
先ほどの訓練手順についてですが、GANの訓練では、以下のようにそれぞれ別々に訓練させるようです。
・Discriminatorの本物画像識別の訓練(訓練画像を利用)
・Discriminatorの偽物画像識別の訓練(Generator生成画像を利用)
・Generatorの本物画像生成の訓練(Discriminator層も利用するが訓練を一時停止)
GANの説明では、Discriminatorは本物か偽物を見分けると書いてあり、Discriminatorに入力した画像が最終的に1か0に判定されるような層になっています。訓練用画像(本物)を入力した際にはラベルを1とし、ノイズ画像(偽物)を入力した際にはラベルを0として固定して(教師データとして)、それぞれを分けて学習させていきます。そうすることで、Discriminator層には本物/偽物を見分ける重み付けが徐々に形成されていきます。
一方Generatorでは、ノイズ画像を本物画像に近づくように訓練しなければいけないのですが、AEやVAEのように具体的な訓練画像を目指してdecodeしていくわけではないので、一体どうやって本物に近づけていくのだろうと疑問に思っていました。
最終的にはGeneratorのノイズ画像が、Discriminator層の最後の1次元の出力層で1(本物)になるようにGenerator層が学習していけばいいということになります。そのためには、Generator単独で訓練するのではなく、Discriminator層も連結してラベル(教師データ)を1に固定して訓練させます。画像を教師データにして訓練するのではなく、本物かどうかというラベルを教師データにして訓練する点がGANの特長だと思います(それでも画像生成は可能)。ただし、二つを連結させると両方とも訓練してしまうので、二つのうちGenarator層だけを訓練させるために、
discriminator.trainable=False
を挿入してDiscriminatorの訓練を一時停止しておく必要があります。
この部分に注意すれば、あとはそれほど難しいアルゴリズムが登場してくることはないかと。解説を読むと数式や抽象的な概念が出てきますが、アルゴリズム的に訓練の手順を理解すればそれほど難しいものではないような気がします。AEではモデル全体は真ん中がくびれていますが、GANの場合は始まりと終わりが細くて真ん中が太くなっているので(decoderとencoderを逆につなげたように)一見わかりにくいという印象です。しかしよくみれば、100次元のノイズを入力元として、decoder(Genarator)で28*28次元のMNIST画像に拡大し(生成画像)、またそれをencoder(Discriminator)で1次元まで落として、最後はsigmoidで0/1判定するという流れになっています。
DCGAN実装:
環境:
Ubuntu 18.04.1
GTX 1060
CUDA 9.0
Python 3.6
Tensorflow 1.9 (Keras 2.1.6)
Jupyter Notebook 5.6
まずはモジュールのインポート。今回もJupyter Notebookで。
次に、各種変数とGenerator層。
次に、Discriminator層。
Dropoutを入れて試してみましたが逆効果となってしまったので、今回はなし。
次は、GenaratorとDiscriminatorの連結層。
まずは、MNISTデータの読み込みと正規化(-1〜1)。そして、Discriminator、Generator、Combined(G + D)モデルの定義。Adamで最適化。
そして訓練ループ。
まずDiscriminatorの訓練をリアル画像とフェイク画像に分けて行います。
訓練はfitではなくtrain_on_batchでバッチごとに行うといいようです。その際にDiscriminatorの場合は、フェイク:0とリアル:1の二つのラベルを教師データとして与えておき、それぞれを別々に訓練し、最後にそのロスを合算しておきます。
次のGeneratorの訓練では、教師データをリアル:1として与えておき、Discriminatorの訓練を一時停止した状態で連結したcombinedモデルを訓練させます。そうすると出力がリアル:1になるようにGeneratorの重み付けが形成されます。この部分がGAN特有の訓練のさせ方だと思います。
d_loss_real=ノイズ-->Generator-->Discriminator-->realラベル(教師データ)
d_loss_fake=ノイズ-->Generator-->Discriminator-->fakeラベル(教師データ)
Discriminator_loss=0.5*(d_loss_real+d_loss_fake)
Generatorの訓練:
g_loss=ノイズ-->Generator-->Discriminator(訓練停止)-->realラベル(教師データ)
という手順でそれぞれを訓練しています。
教師データとなるreal/fakeラベルはbatch_size分用意しておき、train_on_batch()に代入します。
合計10000エポック回して、100エポックごとに各Lossを表示。最後に最終画像を表示。
生成画像結果:

 赤:Discriminator Loss、青:Generator Loss
赤:Discriminator Loss、青:Generator Loss
これをみてもよくわからない。3000エポック以降はあまりかわっていないようなので5000エポックくらいの訓練でもいいのかもしれない。
まとめ:
DCGANは思っていたよりもシンプルな構造で、GeneratorとDiscriminatorをつくれば、あとはそれぞれの訓練の手順を間違わないようにコーディングしていけばいいという感じです。どちらかというとVAEのほうが難しかったという印象です。
ただしDCGANで難しいのは、GeneratorとDiscriminatorの中身の層をどうするか?ということかもしれません。ここを参考にすると、LeakyReLUやBatchNormを使った方がいいらしいのですが、層の順番やパラメータが少し違うだけでも生成画像がノイズのままで終わってしまうので、安定的に画像生成させるにはいろいろ試してみる必要がありそうです。GANの派生型はたくさんあるので、DCGAN以外のGANも試して比較してみたほうがよさそうです。
参考にしたサイト:
https://towardsdatascience.com/having-fun-with-deep-convolutional-gans-f4f8393686ed
https://elix-tech.github.io/ja/2017/02/06/gan.html
https://qiita.com/triwave33/items/1890ccc71fab6cbca87e
https://qiita.com/t-ae/items/236457c29ba85a7579d5
チュートリアルなどでは、
・Autoencoder(AE)
・Variational Autoencoder(VAE)
・Generative Adversarial Networks(GAN)
という順番で説明されていることが多く、VAE(潜在空間、ベイズ推定、KLダイバージェンスなど)を理解しないことにはGANを理解することも難しいかなと勝手に思っていましたが、そもそもAEとVAEも大きく異なるしGANもまた別のアルゴリズムという感じで、基本のAEが分かればGANを理解することはできそうです。
GANの派生型はいろいろありますが、とりあえず今回はDCGANを理解しようと思います。
上の画像はDCGANの構造で、左半分がGeneratorで右半分がDiscriminatorです。最終的にはGenerator層の右端(上画像中央:64x64x3)に画像が生成されます。
まずGeneratorで画像生成する前に、Discriminatorの左端から訓練画像を入力してDiscriminatorだけを教師あり学習します。その後、GeneratorとDiscriminatorを連結させたネットワークで教師あり学習させます。このときDiscriminatorの学習を停止させておいてGeneratorだけが学習するようにします。そうすると既に学習されているDiscriminatorを利用しながらGeneratorだけが学習し、その結果として画像が生成されます。この交互に学習させる手順がわかりにくいので難しく見えるのかもしれません。
GeneratorはAEやVAEのdecoder層だけで構成されている感じで、最初のノイズ画像はVAEで言う潜在空間と呼びますが、途中でReparameterization TrickやKLダイバージェンスなどの複雑な計算を使うこともないので、潜在空間というよりは単なるノイズ画像(np.random.normalで生成)と捉えたほうがよさそうです。
GANの訓練の特長:
先ほどの訓練手順についてですが、GANの訓練では、以下のようにそれぞれ別々に訓練させるようです。
・Discriminatorの本物画像識別の訓練(訓練画像を利用)
・Discriminatorの偽物画像識別の訓練(Generator生成画像を利用)
・Generatorの本物画像生成の訓練(Discriminator層も利用するが訓練を一時停止)
GANの説明では、Discriminatorは本物か偽物を見分けると書いてあり、Discriminatorに入力した画像が最終的に1か0に判定されるような層になっています。訓練用画像(本物)を入力した際にはラベルを1とし、ノイズ画像(偽物)を入力した際にはラベルを0として固定して(教師データとして)、それぞれを分けて学習させていきます。そうすることで、Discriminator層には本物/偽物を見分ける重み付けが徐々に形成されていきます。
一方Generatorでは、ノイズ画像を本物画像に近づくように訓練しなければいけないのですが、AEやVAEのように具体的な訓練画像を目指してdecodeしていくわけではないので、一体どうやって本物に近づけていくのだろうと疑問に思っていました。
最終的にはGeneratorのノイズ画像が、Discriminator層の最後の1次元の出力層で1(本物)になるようにGenerator層が学習していけばいいということになります。そのためには、Generator単独で訓練するのではなく、Discriminator層も連結してラベル(教師データ)を1に固定して訓練させます。画像を教師データにして訓練するのではなく、本物かどうかというラベルを教師データにして訓練する点がGANの特長だと思います(それでも画像生成は可能)。ただし、二つを連結させると両方とも訓練してしまうので、二つのうちGenarator層だけを訓練させるために、
discriminator.trainable=False
を挿入してDiscriminatorの訓練を一時停止しておく必要があります。
この部分に注意すれば、あとはそれほど難しいアルゴリズムが登場してくることはないかと。解説を読むと数式や抽象的な概念が出てきますが、アルゴリズム的に訓練の手順を理解すればそれほど難しいものではないような気がします。AEではモデル全体は真ん中がくびれていますが、GANの場合は始まりと終わりが細くて真ん中が太くなっているので(decoderとencoderを逆につなげたように)一見わかりにくいという印象です。しかしよくみれば、100次元のノイズを入力元として、decoder(Genarator)で28*28次元のMNIST画像に拡大し(生成画像)、またそれをencoder(Discriminator)で1次元まで落として、最後はsigmoidで0/1判定するという流れになっています。
DCGAN実装:
環境:
Ubuntu 18.04.1
GTX 1060
CUDA 9.0
Python 3.6
Tensorflow 1.9 (Keras 2.1.6)
Jupyter Notebook 5.6
まずはモジュールのインポート。今回もJupyter Notebookで。
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, BatchNormalization
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, Activation, LeakyReLU
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
tf.logging.set_verbosity(tf.logging.ERROR)
次に、各種変数とGenerator層。
img_rows = 28
img_cols = 28
channels = 1
img_shape = (img_rows, img_cols, channels)
latent_dim = 100
def generator_model():
model = Sequential()
model.add(Dense(1024, input_shape=(latent_dim,)))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Dense(7*7*128))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Reshape((7,7,128)))
model.add(Conv2DTranspose(64, kernel_size=5, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(1,kernel_size=5, strides=2, padding='same'))
model.add(Activation('tanh'))
return model
次に、Discriminator層。
def discriminator_model():
model = Sequential()
model.add(Conv2D(32, kernel_size=5, strides=2,padding='same', input_shape=img_shape))
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(16,kernel_size=5,strides=2, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Flatten())
model.add(Dense(784))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
Dropoutを入れて試してみましたが逆効果となってしまったので、今回はなし。
次は、GenaratorとDiscriminatorの連結層。
def combined_model():
discriminator.trainable = False
model = Sequential([generator, discriminator])
return model
まずは、MNISTデータの読み込みと正規化(-1〜1)。そして、Discriminator、Generator、Combined(G + D)モデルの定義。Adamで最適化。
(x_train, _), (_, _) = mnist.load_data()
x_train = (x_train.astype('float32') - 127.5) / 127.5
x_train = x_train.reshape(-1, 28, 28, 1)
# Discriminator Model
discriminator = discriminator_model()
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
# Generator Model
generator = generator_model()
# Combined(G + D) Model
combined = combined_model()
combined.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.00015, beta_1=0.5))
そして訓練ループ。
まずDiscriminatorの訓練をリアル画像とフェイク画像に分けて行います。
訓練はfitではなくtrain_on_batchでバッチごとに行うといいようです。その際にDiscriminatorの場合は、フェイク:0とリアル:1の二つのラベルを教師データとして与えておき、それぞれを別々に訓練し、最後にそのロスを合算しておきます。
次のGeneratorの訓練では、教師データをリアル:1として与えておき、Discriminatorの訓練を一時停止した状態で連結したcombinedモデルを訓練させます。そうすると出力がリアル:1になるようにGeneratorの重み付けが形成されます。この部分がGAN特有の訓練のさせ方だと思います。
batch_size = 32
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
epochs = 10000
Loss_D = []
Loss_G = []
import time
start = time.time()
for epoch in range(epochs):
# shuffle batch data
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs = x_train[idx]
# Train Discriminator
# sample noise images to generator
noise = np.random.normal(0, 1, (batch_size, latent_dim))
gen_imgs = generator.predict(noise)
# train discriminator real and fake
d_loss_real = discriminator.train_on_batch(imgs, real)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# Train Generator
g_loss = combined.train_on_batch(noise, real)
Loss_D.append(d_loss[0])
Loss_G.append(g_loss)
if epoch % 100 == 0:
print("%04d [D loss: %f, acc.: %.2f%%] [G loss: %f] %.2f sec" % (epoch, d_loss[0], 100*d_loss[1], g_loss, time.time()-start))
if epoch == epochs - 1:
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, latent_dim))
gen_imgs = generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
plt.show() d_loss_real=ノイズ-->Generator-->Discriminator-->realラベル(教師データ)
d_loss_fake=ノイズ-->Generator-->Discriminator-->fakeラベル(教師データ)
Discriminator_loss=0.5*(d_loss_real+d_loss_fake)
Generatorの訓練:
g_loss=ノイズ-->Generator-->Discriminator(訓練停止)-->realラベル(教師データ)
という手順でそれぞれを訓練しています。
教師データとなるreal/fakeラベルはbatch_size分用意しておき、train_on_batch()に代入します。
合計10000エポック回して、100エポックごとに各Lossを表示。最後に最終画像を表示。
生成画像結果:
生成画像(10000エポック)。
途中の画像も見てみましたが、5000エポックくらいでもそこそこ識別できるレベルにはなりましたが、10000エポックくらい回したほうがよさそうです(GTX1060で約6分、Macだと1時間はかかりそう)。モード崩壊(似たような画像ばかりになる現象)は発生していないようです。
 生成画像(5000エポック)。やや不明瞭??
生成画像(5000エポック)。やや不明瞭??
 生成画像(2500エポック)。
生成画像(2500エポック)。

以下のコードでLossを表示。
生成画像(2000エポック)。このあたりだとやはり不鮮明。
以下のコードでLossを表示。
plt.plot(np.arange(epochs), Loss_D, 'r-')
plt.plot(np.arange(epochs), Loss_G, 'b-')
これをみてもよくわからない。3000エポック以降はあまりかわっていないようなので5000エポックくらいの訓練でもいいのかもしれない。
まとめ:
DCGANは思っていたよりもシンプルな構造で、GeneratorとDiscriminatorをつくれば、あとはそれぞれの訓練の手順を間違わないようにコーディングしていけばいいという感じです。どちらかというとVAEのほうが難しかったという印象です。
ただしDCGANで難しいのは、GeneratorとDiscriminatorの中身の層をどうするか?ということかもしれません。ここを参考にすると、LeakyReLUやBatchNormを使った方がいいらしいのですが、層の順番やパラメータが少し違うだけでも生成画像がノイズのままで終わってしまうので、安定的に画像生成させるにはいろいろ試してみる必要がありそうです。GANの派生型はたくさんあるので、DCGAN以外のGANも試して比較してみたほうがよさそうです。
参考にしたサイト:
https://towardsdatascience.com/having-fun-with-deep-convolutional-gans-f4f8393686ed
https://elix-tech.github.io/ja/2017/02/06/gan.html
https://qiita.com/triwave33/items/1890ccc71fab6cbca87e
https://qiita.com/t-ae/items/236457c29ba85a7579d5