GPU(GTX1060)ゲーミングノートパソコンがあるので、仮想通貨のマイニングを試してみました。一般的にマイニングはあまり儲からないと聞きますが、どの程度なのか実際確かめてみることにしました。ビットコインは、もうすでに100万円を越しており、マイニングするにも電気代がものすごくかかるようで、
GPUマシンをフル回転させるため、機材と電気代を合わせるとなかなか採算とれないようで、そのかわり一切を業者に頼むクラウドマイニングというシステムもあるようです。クラウド上のGPUマシンを使ってマイニングするという感じでしょうか。
国内でもモナーコイン(2013年12月〜)という仮想通貨があるようで、まだまだ人気はないようですが、
 coingecko.comより
coingecko.comより
突然ここ数ヶ月で数十円から一気に700円くらいまで値上っています。
ということで、この急上昇中のモナーコインで発掘(マイニング)をしてみました。方法についてはネットで検索するといろいろ出てきますが、一応簡単にやってみた手順を書いておきます。
Linux(Ubuntu)で試そうと思いましたが、LinuxやMacだとソースをコンパイルする必要があり、エラーで上手くコンパイルされないためにWindows版に切り替えました。Windows版はすでにバイナリのアプリがダウンロードできるので簡単です。
準備:
(1)モナーコインのウォレット/財布(モナーコインサイトからダウンロード)
(2)マイニングプールへ登録(グループで採掘:とりあえずvip poolというグループ)
それぞれの手続や入力項目はありますが、この3つですぐに始められました。
基本的には、発掘ソフトでモナーコインを発掘し、得たモナーコインを財布にためていくだけです。
マイニングプールは、グループに所属して作業量などに応じて発掘されたモナーを分配する仕組みのようです。ソロで発掘すれば、独り占めできるようですが、そのためにはかなりパイスペックな機材が必要らしいので、一般的なパソコンを使って発掘するにはグループに所属したほうがいいらしいです。
 AliExpress.com Product - YUNHUI Newest Bitcoin Miner Ebit E9 Plus 9T 14nm Asic Miner BTC Miner better than Antminer S7 and high Cost-effectiv than S9 .262,276円(送料無料)AliExpressでもハイスペックなマイニングマシンが売っています。GPUよりすごいASICというマイニングマシンです。以前から中国が世界中のマイニングを行っていましたが、マイニングが規制されたため中古品などが多く出回っているそうです。
AliExpress.com Product - YUNHUI Newest Bitcoin Miner Ebit E9 Plus 9T 14nm Asic Miner BTC Miner better than Antminer S7 and high Cost-effectiv than S9 .262,276円(送料無料)AliExpressでもハイスペックなマイニングマシンが売っています。GPUよりすごいASICというマイニングマシンです。以前から中国が世界中のマイニングを行っていましたが、マイニングが規制されたため中古品などが多く出回っているそうです。
(1)のモナーコインのウォレット/財布は、発掘したモナーをためておく銀行口座のようなもので送金/入金をこのソフトで行うようです。しかし、(2)のマイニングプールに所属していれば、一時的にそのグループ内のアカウントに発掘したモナーを貯めておくこともできるので、ある程度貯まったら(1)のウォレットへ送金するということになるようです。
ダウンロード自体はすぐですが、一旦立ち上げるとネットワークと同期する必要があるようで、けっこう時間がかかるためしばらく放置しておきます。数時間はかかるので、その間に次のステップ:受取口座(アドレス)をつくっておきます。
C:¥Program Files¥Monacoin¥monacoin-qt.exe
がこのウォレットソフトになります。
それとは別の場所の
C:¥ユーザー¥user¥AppData¥Roaming¥Monacoin(フォルダ)
このフォルダにはその他必要な設定ファイルやバックアップファイルなどが入っています。
読み込み中の内容を見ると、過去数年前まで遡ってモナーコインのすべての取引データを読み込んでいるようです。ということは10年経てば10年分のデータを各自のパソコンが読み込まなければいけないということになりそうです。仮想コインは中央集権型ではなく、分散型で各自利用者が銀行のような業務を担うのだと思うのですが、それにしてもどんどんデータ(取引台帳)がかさんでいくのでパソコンのハードディスクもそこそこ残しておかないとだめかもしれません。ウォレットソフト自体は数十MBですが、設定ファイルなどが入っているほうのMonacoinフォルダは2GBくらいあります。
 ウォレット内の「入金(R)」をクリックして「ラベル」に適当な名前をつけて、支払いを「リクエストする(R)」を押すと、受取用アドレスができ、QRコードとともにMで始まる長い文字列アドレス(振り込んでもらう口座番号)ができあがります。毎回のトランザクションごとに新しいアドレスをつくったほうがいいと書いてあるので、その都度アドレス(振込先)が変わるようです。
ウォレット内の「入金(R)」をクリックして「ラベル」に適当な名前をつけて、支払いを「リクエストする(R)」を押すと、受取用アドレスができ、QRコードとともにMで始まる長い文字列アドレス(振り込んでもらう口座番号)ができあがります。毎回のトランザクションごとに新しいアドレスをつくったほうがいいと書いてあるので、その都度アドレス(振込先)が変わるようです。
ここで、一つ受取アドレスをつくっておいて、それを以下のマイニングプールからの受取に使います。
(2)のマイニングプールはグループで採掘する採掘所のようなもので、所属していればその働きに応じて利益を分配してくれるようです。
登録するには、以下のような項目を入力して認証メール受け取り後ログインできるようになります。
 どうやらこのサイトのサーバを介して発掘しているようで、このサイトで各種設定や状況などを確認できるようです。このvip poolにおけるユーザー名/パスワードを決め、Monacoinアドレスには(1)のウォレットでつくった受取アドレスを記入(この部分は後で変えられるはず)、PIN番号はvip pool内で設定変更などしたときの認証番号です(適当な4桁)。
どうやらこのサイトのサーバを介して発掘しているようで、このサイトで各種設定や状況などを確認できるようです。このvip poolにおけるユーザー名/パスワードを決め、Monacoinアドレスには(1)のウォレットでつくった受取アドレスを記入(この部分は後で変えられるはず)、PIN番号はvip pool内で設定変更などしたときの認証番号です(適当な4桁)。
ログインしたら、アカウント>ワーカーへ行き、「新しいワーカーの追加」をします。
 とりあえず適当な名前とパスワードを記入し、「ワーカーの追加」ボタンを押します。「指定Difficulty」という設定があるので、パソコンのスペックに合わせてその値を決めます。GTX1060だと8か16くらい。普通のCPUだともっと低くて0.125などとなるようです。Hashrateはパソコンのスペックに応じた発掘能力のようで、自動で切り替わったり、あとで変更も可能なので、注意書きにある参考値を元にとりあえず記入しておきます。
とりあえず適当な名前とパスワードを記入し、「ワーカーの追加」ボタンを押します。「指定Difficulty」という設定があるので、パソコンのスペックに合わせてその値を決めます。GTX1060だと8か16くらい。普通のCPUだともっと低くて0.125などとなるようです。Hashrateはパソコンのスペックに応じた発掘能力のようで、自動で切り替わったり、あとで変更も可能なので、注意書きにある参考値を元にとりあえず記入しておきます。
この設定したワーカーで発掘することになりますが、通常は一つつくればいいのだと思います。
あとは以下の発掘ソフトを起動するだけです。
(3)の採掘ソフトは、CPU用ならcpuminer、GPU/Radeonならsgminer、GPU/Nvidiaならccminerと分かれています。採掘ソフトの設定次第ではソロでも採掘できるようです。ソロの場合は(3)で採掘したモナーコインを直接(1)のウォレットへ送金するというかたちになるようです。
この採掘用ソフトが、LinuxとMacの場合はgithubにあるソースをコンパイルする必要があり、コンパイル中にエラーばかりでてしまいました。Windowsの場合は、ダウンロードすればコンパイル済みのアプリが入っているので、設定項目を追記すればすぐに使うことができます。
ちなみにvip poolというグループに所属し、以下の採掘ソフトを使ってみました。
ccminer-djm34-mod-r1(採掘ソフト)の場合:
ダウンロード/解凍すると、
djm34-mod-r1 フォルダ
└ ccminer-djm34-mod-r1 フォルダ
├ ccminer アプリケーション
├ LYRA2REv2-START バッチファイル
└ vcrumtime140.dll
というファイルがあり、
LYRA2REv2-STARTをエディタで開き、既に書いてある内容を一旦消して以下だけを記入。
ccminer.exe -a lyra2v2 -o stratum+tcp://vippool.net:8888 -u loginname.workername -p workerpassword
loginnameにはvip poolへ登録したログイン名、ドットを挟んでworkernameはvip pool内で設定したworker名、workerpasswordはworker用のパスワード。
このLYRA2REv2-STARTは、.batファイルなので、そのままダブルクリックするとコマンドプロンプトが立ち上がってすぐに採掘を開始します。
 こんな感じで、コマンドプロンプトに採掘状況が出てきます。「yes!」なら採掘成功、「booooo」なら失敗。たまに失敗しつつ、比較的多く10秒おきくらいに「yes!」が出てきます。しかし、「yes!」が出たからと言って、すぐに報酬につながるわけでもなさそうです。
こんな感じで、コマンドプロンプトに採掘状況が出てきます。「yes!」なら採掘成功、「booooo」なら失敗。たまに失敗しつつ、比較的多く10秒おきくらいに「yes!」が出てきます。しかし、「yes!」が出たからと言って、すぐに報酬につながるわけでもなさそうです。
報酬につながるためにはブロックを発見しなければいけないようで、グループで作業しても1時間に1〜3回程度です。このへんの仕組みがまだ良くわからないのですが、「yes!」が出れば一応仕事をしているという感じです。
結果(マイニングプールで24時間稼働):
24時間放置して動かしてみた結果です。
 ベストな設定なのかわかりませんが、結果的に24時間で0.17863435モナ獲得できました。現在1モナは700円前後なので、約125円/日ということです。
ベストな設定なのかわかりませんが、結果的に24時間で0.17863435モナ獲得できました。現在1モナは700円前後なので、約125円/日ということです。
ここで電気代についても見てみると(こちらの電気代計算サイトより)、
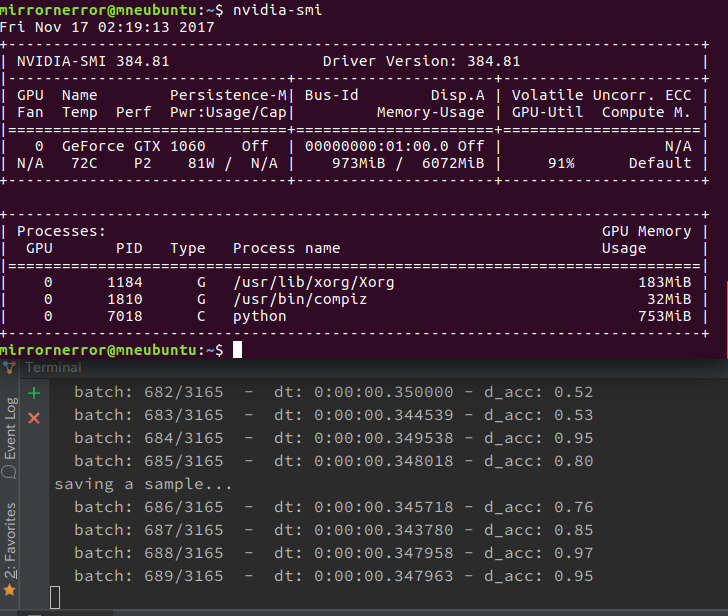
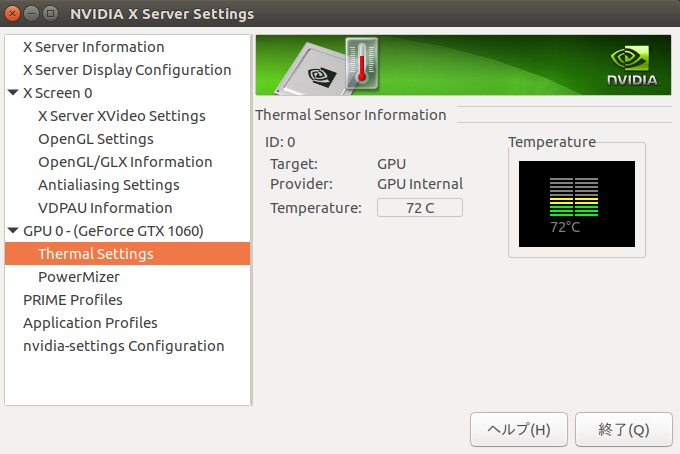
 nvidia-smi.exeでGTX1060の稼働状況を見てみると70W/h前後でした。ということで、上画像にあるように約40円/日かかっています。
nvidia-smi.exeでGTX1060の稼働状況を見てみると70W/h前後でした。ということで、上画像にあるように約40円/日かかっています。
つまり現在のモナーコインレートで換算すれば、125-45=85円/日プラスという結果が得られました。当然モナーコインの価値が下がれば、その分利益も低くなってしまいます。
ソロマイニングを試す:
採掘ソフトであるccminerにはソロ採掘設定もあるので、比較のため試してみることに。ソロマイニングは確率は低いですが一回の報酬を独り占め(25mona:レート700円なら17,500円)できるようです。
まずC:>ユーザー>user>AppData>Roaming>Monacoin内にmonacoin.confというファイルをつくります。このとき拡張子ありでファイル名を見るとmonacoin.conf.txtになっていることもあるので、.txtはつけないで保存します。
その中にエディタなどで以下を記入:
rpcuser=user
rpcpassword=password
rpcallowip=192.168.0.0/255.255.0.0
rpcallowip=127.0.0.1
rpcport=4444
次に今までマイニングプールで使っていたLYRA2REv2-START.batファイルの複製をつくり、LYRA2REv2-SOLO.batなどと名前変更してソロ用の設定に書き換えます。
ccminer.exe -a lyra2v2 -o 127.0.0.1:4444 -u name -p password --no-longpoll --no-getwork --coinbase-addr=walletaddress
-u name -p passwordは、monacoin.confの中のrpcuser=user、rpcpassword=passwordと同じものです。walletaddressには、モナーコインウォレットでつくったmから始まる入金アドレス。ipアドレスの部分は基本的にこのままで大丈夫です。
ソロマイニング起動:
まず、monacoin-qt.exe(ウォレット)を起動します。これがサーバとなるようです。そして今つくったLYRA2REv2-SOLO.batをダブルクリックすればソロマイニングが始まります。
追記:
その後ソロマイニングでやっと一回(25モナコイン)をゲットできました。
 やはり、ソロマイニングだとまったくヒットしません。何日間かやって、やっと一回当たるくらいの確率らしく、ほとんど運次第のようです。グループでマイニングしたほうが少なからず分配報酬があるので、まだましなのかもしれませんが、ゲーム感覚でするなら一攫千金的なソロマイニングのほうが面白そうです。
やはり、ソロマイニングだとまったくヒットしません。何日間かやって、やっと一回当たるくらいの確率らしく、ほとんど運次第のようです。グループでマイニングしたほうが少なからず分配報酬があるので、まだましなのかもしれませんが、ゲーム感覚でするなら一攫千金的なソロマイニングのほうが面白そうです。
獲得したモナーコインは、ZaifやbitFlyerなどの取引所で円に交換できるようです。そのためにはZaifやbitFlyerのアカウントが必要となります。
「仮想通貨のマイニングに使用された電力、すでに世界159カ国の年間使用量を上回る」
このようにニュースでも騒がれています。とは言ってもその他の仮想通貨もどんどん出てきており、今後破綻する仮想通貨もでてくるのだと思いますが、エネルギーや経済のシステムがどんどん変わりそうです。GPUマシンをフル回転させるため、機材と電気代を合わせるとなかなか採算とれないようで、そのかわり一切を業者に頼むクラウドマイニングというシステムもあるようです。クラウド上のGPUマシンを使ってマイニングするという感じでしょうか。
国内でもモナーコイン(2013年12月〜)という仮想通貨があるようで、まだまだ人気はないようですが、

突然ここ数ヶ月で数十円から一気に700円くらいまで値上っています。
ということで、この急上昇中のモナーコインで発掘(マイニング)をしてみました。方法についてはネットで検索するといろいろ出てきますが、一応簡単にやってみた手順を書いておきます。
Linux(Ubuntu)で試そうと思いましたが、LinuxやMacだとソースをコンパイルする必要があり、エラーで上手くコンパイルされないためにWindows版に切り替えました。Windows版はすでにバイナリのアプリがダウンロードできるので簡単です。
準備:
(1)モナーコインのウォレット/財布(モナーコインサイトからダウンロード)
(2)マイニングプールへ登録(グループで採掘:とりあえずvip poolというグループ)
(3)発掘ソフトをダウンロード(ここを参考に)
それぞれの手続や入力項目はありますが、この3つですぐに始められました。
基本的には、発掘ソフトでモナーコインを発掘し、得たモナーコインを財布にためていくだけです。
マイニングプールは、グループに所属して作業量などに応じて発掘されたモナーを分配する仕組みのようです。ソロで発掘すれば、独り占めできるようですが、そのためにはかなりパイスペックな機材が必要らしいので、一般的なパソコンを使って発掘するにはグループに所属したほうがいいらしいです。
 AliExpress.com Product - YUNHUI Newest Bitcoin Miner Ebit E9 Plus 9T 14nm Asic Miner BTC Miner better than Antminer S7 and high Cost-effectiv than S9 .262,276円(送料無料)AliExpressでもハイスペックなマイニングマシンが売っています。GPUよりすごいASICというマイニングマシンです。以前から中国が世界中のマイニングを行っていましたが、マイニングが規制されたため中古品などが多く出回っているそうです。
AliExpress.com Product - YUNHUI Newest Bitcoin Miner Ebit E9 Plus 9T 14nm Asic Miner BTC Miner better than Antminer S7 and high Cost-effectiv than S9 .262,276円(送料無料)AliExpressでもハイスペックなマイニングマシンが売っています。GPUよりすごいASICというマイニングマシンです。以前から中国が世界中のマイニングを行っていましたが、マイニングが規制されたため中古品などが多く出回っているそうです。(1)のモナーコインのウォレット/財布は、発掘したモナーをためておく銀行口座のようなもので送金/入金をこのソフトで行うようです。しかし、(2)のマイニングプールに所属していれば、一時的にそのグループ内のアカウントに発掘したモナーを貯めておくこともできるので、ある程度貯まったら(1)のウォレットへ送金するということになるようです。
ダウンロード自体はすぐですが、一旦立ち上げるとネットワークと同期する必要があるようで、けっこう時間がかかるためしばらく放置しておきます。数時間はかかるので、その間に次のステップ:受取口座(アドレス)をつくっておきます。
C:¥Program Files¥Monacoin¥monacoin-qt.exe
がこのウォレットソフトになります。
それとは別の場所の
C:¥ユーザー¥user¥AppData¥Roaming¥Monacoin(フォルダ)
このフォルダにはその他必要な設定ファイルやバックアップファイルなどが入っています。
読み込み中の内容を見ると、過去数年前まで遡ってモナーコインのすべての取引データを読み込んでいるようです。ということは10年経てば10年分のデータを各自のパソコンが読み込まなければいけないということになりそうです。仮想コインは中央集権型ではなく、分散型で各自利用者が銀行のような業務を担うのだと思うのですが、それにしてもどんどんデータ(取引台帳)がかさんでいくのでパソコンのハードディスクもそこそこ残しておかないとだめかもしれません。ウォレットソフト自体は数十MBですが、設定ファイルなどが入っているほうのMonacoinフォルダは2GBくらいあります。

ここで、一つ受取アドレスをつくっておいて、それを以下のマイニングプールからの受取に使います。
(2)のマイニングプールはグループで採掘する採掘所のようなもので、所属していればその働きに応じて利益を分配してくれるようです。
登録するには、以下のような項目を入力して認証メール受け取り後ログインできるようになります。

ログインしたら、アカウント>ワーカーへ行き、「新しいワーカーの追加」をします。

この設定したワーカーで発掘することになりますが、通常は一つつくればいいのだと思います。
あとは以下の発掘ソフトを起動するだけです。
(3)の採掘ソフトは、CPU用ならcpuminer、GPU/Radeonならsgminer、GPU/Nvidiaならccminerと分かれています。採掘ソフトの設定次第ではソロでも採掘できるようです。ソロの場合は(3)で採掘したモナーコインを直接(1)のウォレットへ送金するというかたちになるようです。
この採掘用ソフトが、LinuxとMacの場合はgithubにあるソースをコンパイルする必要があり、コンパイル中にエラーばかりでてしまいました。Windowsの場合は、ダウンロードすればコンパイル済みのアプリが入っているので、設定項目を追記すればすぐに使うことができます。
ちなみにvip poolというグループに所属し、以下の採掘ソフトを使ってみました。
ccminer-djm34-mod-r1(採掘ソフト)の場合:
ダウンロード/解凍すると、
djm34-mod-r1 フォルダ
└ ccminer-djm34-mod-r1 フォルダ
├ ccminer アプリケーション
├ LYRA2REv2-START バッチファイル
└ vcrumtime140.dll
というファイルがあり、
LYRA2REv2-STARTをエディタで開き、既に書いてある内容を一旦消して以下だけを記入。
ccminer.exe -a lyra2v2 -o stratum+tcp://vippool.net:8888 -u loginname.workername -p workerpassword
loginnameにはvip poolへ登録したログイン名、ドットを挟んでworkernameはvip pool内で設定したworker名、workerpasswordはworker用のパスワード。
このLYRA2REv2-STARTは、.batファイルなので、そのままダブルクリックするとコマンドプロンプトが立ち上がってすぐに採掘を開始します。

報酬につながるためにはブロックを発見しなければいけないようで、グループで作業しても1時間に1〜3回程度です。このへんの仕組みがまだ良くわからないのですが、「yes!」が出れば一応仕事をしているという感じです。
結果(マイニングプールで24時間稼働):
24時間放置して動かしてみた結果です。

ここで電気代についても見てみると(こちらの電気代計算サイトより)、

つまり現在のモナーコインレートで換算すれば、125-45=85円/日プラスという結果が得られました。当然モナーコインの価値が下がれば、その分利益も低くなってしまいます。
ソロマイニングを試す:
採掘ソフトであるccminerにはソロ採掘設定もあるので、比較のため試してみることに。ソロマイニングは確率は低いですが一回の報酬を独り占め(25mona:レート700円なら17,500円)できるようです。
まずC:>ユーザー>user>AppData>Roaming>Monacoin内にmonacoin.confというファイルをつくります。このとき拡張子ありでファイル名を見るとmonacoin.conf.txtになっていることもあるので、.txtはつけないで保存します。
その中にエディタなどで以下を記入:
rpcuser=user
rpcpassword=password
rpcallowip=192.168.0.0/255.255.0.0
rpcallowip=127.0.0.1
rpcport=4444
次に今までマイニングプールで使っていたLYRA2REv2-START.batファイルの複製をつくり、LYRA2REv2-SOLO.batなどと名前変更してソロ用の設定に書き換えます。
ccminer.exe -a lyra2v2 -o 127.0.0.1:4444 -u name -p password --no-longpoll --no-getwork --coinbase-addr=walletaddress
-u name -p passwordは、monacoin.confの中のrpcuser=user、rpcpassword=passwordと同じものです。walletaddressには、モナーコインウォレットでつくったmから始まる入金アドレス。ipアドレスの部分は基本的にこのままで大丈夫です。
ソロマイニング起動:
まず、monacoin-qt.exe(ウォレット)を起動します。これがサーバとなるようです。そして今つくったLYRA2REv2-SOLO.batをダブルクリックすればソロマイニングが始まります。
追記:
その後ソロマイニングでやっと一回(25モナコイン)をゲットできました。

獲得したモナーコインは、ZaifやbitFlyerなどの取引所で円に交換できるようです。そのためにはZaifやbitFlyerのアカウントが必要となります。


NiceHash Miner:
そのほか、NiceHash Minerというプールマイニングも試してみました。セッティングも簡単で、すぐに始めることができました。


コマンドプロンプトが出てきますが、基本的には画面のスタートボタンを押すだけで勝手に採掘開始します。

計算で収益を求める:
どうやらそのパソコンの計算能力/採掘能力のことをハッシュレート/hashrateと呼び、NVIDIAのGPUであれば、
GTX1050 10.01MH/s
GTX1050Ti 11.49MH/s
GTX1060 23.39MH/s
GTX1070 35.88MH/s
GTX1080 47.68MH/s
GTX1080Ti 58.05MH/s
という感じで、数値が大きいほど能力が高い。
それに対し、各仮想通貨におけるDifficultyという暗号解読の難解さの指標もあるようで、現在のビットコインなんかはものすごくDifficultyが高いようです。
24時間あたりの報酬は、
hashrate(kh/s)/Difficulty=報酬(1日)
で概算できるようです(こちらを参考に)。
GTX1060を使用、現在のモナコインのDifficultyはこのサイトを参考にすると約59000、
23390/59000=約0.40
となり、1モナ=800円ならば、
0.40モナ=320円/日
となるようです。もし、ソロマイニングするなら一回堀り当たれば25モナの報酬がもらえるので、
25/0.4=62.5日間
となり、毎日掘り続けても約2ヶ月に1回掘り当てるくらいの確率になるらしい。1モナ=800円なら、一回掘り当てて20000円になるので、確率的には10000円/月という感じでしょうか。
ブロックチェーンアルゴリズムには興味ありましたが(仮想通貨そのものにはそれほど興味なく)、仮想通貨の世界もいろいろ進化しているようです。仮想通貨以外にもトークン(仮想通貨の株式みたいなものらしい)と呼ばれるものも数多く存在し、どんどん従来の経済の仕組みが変わっていきそうです。仮想通貨に興味なくても、一応知っておいたほうが今後のためにもなると思います。
追記:(2017/12/07)
Nicehashのソフトはインストールしたもののあまり使っていませんでした。数日後ためしにつなげてみようとしてもつながらないのでネットで調べてみると、以下のようなニュースが。
「ビットコイン盗まれた」76億円相当か マイニングプール「NiceHash」ハッキング被害
このようなトラブルが起きたようで当然サイトがストップしていました。内部関係者の仕業とも噂されていますが、真相はまだわからないようです。いずれにせよ、Nicehashに預けておいたビットコインはもう戻ってこないでしょう。個人的には16円くらいの損害ですが、Nicehashの場合はたしか最低0.01ビットコイン以上(今のレートであれば17000円)でなければ途中出金不可だったはず(そこまで貯めるにも数ヶ月はかかる)。そのため引き出したくても引き出せない仕組みになっています。基本的には、ほぼ保証ということがない世界でもあるため、稼いだらすぐに自分のウォレットに移動というのが理想的な管理方法ですが、今回の場合はそうもできない人も多くいたということです。Mt.Gox事件のときもそうですが、一見きちんとした取引所であっても突然消滅することはあるので、こまめに手元に送金して保管しておいたほうがよさそうです。
追記:
その後NiceHashにアクセスしてみたところ復活してはいますが、アプリを立ち上げてみたら案の定以前マイニングした約16円分はゼロになっていました。
それとは裏腹に、数日も経たないうちにモナーコインが2000円突破してしまいました。あっという間です。同様にビットコインのほうもどんどん値上がっています。ビットコインは現在180万円ちかくまで高騰していますが、年内中に200万円突破しそうな勢いです。いろいろな仮想通貨やトークンが出ていますが、中途半端な通貨は人気がでなくて、王道のビットコインに一極集中していきそうです。まだまだ値上がるのではないでしょうか?
最近もビットコインは着実に上昇していて、年内には200万円突破するかもしれないと言われていましたが、あっというまに突破してしまいました。少し調べてみると、この1ビットコイン=200万円という数字は、現在流通している貨幣なかでも5番目に規模の大きい通貨となっているようです(参照:bittimes)。
アメリカドル:1兆4200ドル(150兆円)
ユーロ:1兆2100億ドル
中国元:1兆ドル
日本円:8560億ドル
ビットコイン:3000億ドル
インドルピー:2500億ドル
ロシアルーブル:1170億ドル
イギリスポンド:1030億ドル
というランキングになっているようです。5位だったインドルピーを抜き、4位の日本円を抜くにはまだ半分以下ですが、もしかしたら数年以内に抜いてしまうのかもしれません。

また仮想通貨全体では、
4457億ドルであり、ビットコインだけで67.0%を占めているようです。ブロックチェーンという機能的なメリットというよりも(他の仮想通貨で機能的に優れているものも多いはずなのに)、単にネームバリューだけで人気を稼いでいるかのようです。取引されている上場仮想通貨は1334種類もあるようですが、ビットコインがあくまで先頭を走っています。
ちなみにモナコインは少し落ち着いたようで2000円前後を上下しています。
それでもここ数週間で一気に値上がったこともあり、現在19位というのがすごい。年内3000円行くかもしれないと言われていますが、それよりもビットコインの上昇に歯止めが効かなくなっている状態なので、多くの人はビットコインの動向に注目しており、他の仮想通貨はやや注目されにくい状況なのかもしれません。

また他のマーケットとの比較では(上図はやや古い数値になっていますが)、現在ではビットコインだけで$300B(3000億ドル)であることから、アマゾン時価総額に追いつこうとしています(仮想通貨全体ではほぼアマゾンと並んでいる状態)。その上にはApple、そして米ドル、金などとまだまだ先はあるのですが、少しずつビットコイン市場へそれらの貨幣が移動してくれば、まだまだ成長する余地がありそうです。
今から約5倍値上がって、1ビットコイン=1000万円ともなるとアメリカドルと並んでしまうので、そこを目指しているのか、それともそれ以上になろうとしているのか、もしそうなってしまえば、かなり経済の仕組みは変わりそうです。
その後、数日でビットコインは180万円くらいまで下落しています。つい先日までは時価総額3000億ドルありましたが、現在は2624億ドルまで減っています。

というのも、ビットコインは上位1000人ほどが40%を独占しているようで、その人達によって価格操作も可能のようです。
この人達の思惑はどのような方向を向いているのかわかりませんが、ドルを越える世界一の通貨にしようとしているのか、あるいは途中で何かに乗り換えるのか、いずれにせよしばらくは上下に揺さぶりながら、少しずつ時価総額を増やしつつ上り詰めるのではないでしょうか。